Binary search is one of the simplest yet most useful algorithms in terms of both theory and practice and has been one of the backbone for developing many applications including machine learning, computer graphics and database systems. This algorithm stands out because it effectively helps search for items in a sorted list, which makes it an essential part of developers’ toolkit when dealing with sorted data.
Find high-paying, long-term remote Java jobs with top US, UK, and EU companies at Index.dev. Join now!
What is Binary Search Algorithm?
The binary search algorithm, as one of the quickest methods to search for an element in a list, is based on sequentially dividing the list by halves to find the value or until the list is depleted. This divide-and-conquer approach also contributes to a considerable reduction in the time complexity compared to the linear search algorithm which ensures it is used in several applications.
Why is Binary Search Algorithm Important?
The binary search algorithm has several uses and therefore it is important for the following reasons. Firstly, it is easily implemented because of the ease of understanding and the simple mathematical algorithm that they use. Second, it also offers high efficiency, especially for big data sets, reducing time complexity to logN. This efficiency is important in areas that necessitate speedy processing of workloads and a fast rate of return. Moreover, the algorithm makes use of logarithmic time complexity thus making it very efficient when working with large data sets because it halves the number of data points on each call.
How Does the Binary Search Algorithm Work?
When exploring the vast world of sorted data that programmers have created, the binary search algorithm is not only impressive but also remarkable. Unlike in linear search where one goes through each member of a list, binary search divides members into two parts then conquers the part that likely contains the key. Suppose there is a huge sorted array – a storeroom full of mysteries, and you have a single unique key which opens one secret. In linear search, every element gets matched very carefully, which perhaps would require executing a search from beginning to the end of the array. Binary search, however, relies on the fact that this treasure trove is sorted. It starts at the beginning of the array then immediately accesses the midway or center of the array. When seeking the target value in the array, if the key held exceeds this middle element in sorted order, the second half of the array becomes meaningless.
However, if it happens to be below the middle element, then the first half of the array is considered to be a part of the worthless divisions. This process of narrowing down the search to the other half of the list of candidates is a cyclical one. At each stage a comparison is made between the target value and the value at the middle of the first half of the list to ascertain in which half the search should follow. This continues until the target value is successfully placed in its intended position in the array, or the search process ends in the conclusion that the target value does not exist. Due to its sorted structure and properly implemented use of comparisons, binary search significantly diminishes the number of comparisons needed, placing it among the true leaders of efficient data search operations.
Binary Search Implementation
Binary search, also known as logarithmic search or half-interval search, is a cornerstone of efficient searching in computer science. Unlike linear search, which examines each element in a list sequentially, binary search leverages the power of a sorted array to achieve significant speedups. This article delves into the intricate details of implementing a binary search algorithm, dissecting its inner workings and exploring various implementation strategies.
Core Principles: Divide and Conquer
The binary search algorithm also falls under the divide-and-conquer approach. It begins by finding the middle element of the sorted array specifically. If the middle value corresponds to the targeted value, then the search is said to be complete. Otherwise, the algorithm eliminates half of the array based on the position of the target value with respect to the middle element. It then proceeds on the search on the rest of the array and repeats the steps wherein it divides the array into halves and compares the target value to the middle element. This process of elimination of search space is continued until either the target value is obtained or the search space is all utilized and the absence of the target value is suggested.
Implementation Strategies
The binary search algorithm can be implemented iteratively or recursively.
Iterative Approach:
This approach divides the search space again and again by using the loop. It maintains three variables:
- left: Keeps the track of start position or the first element of the current search sub-array.
- right: Keeps the count of the last element with a match in the current sub-array obtained by the search operation.
- mid: Stands for the current position of the middle element during the search of elements relevant to the query in the array.
During each step of the execution, the value of the target is compared with the value of a middle element. If a match is found, the search is successful. Otherwise, it updates the left or right position depending on the location of the target value with respect to the middle element of the subarray which is responsible for eliminating half of the search space. It executes an infinite loop and goes on searching for the target until left becomes greater than right.
Recursive Approach:
The recursive method establishes a function which includes our sorted array, the key value, the left index and the right index. The base case happens when the left pointer becomes larger than the right one, which means the search was unsuccessful. If not, the function determines the middle index and checks if the target exists by comparing the target with the middle element. It then continues to call itself on the right or left parts of the search space depending on how it compares.
Choosing the Right Approach
It is conventional to decide whether to employ iterative or recursive methodologies straightforwardly based on the personal choice of programmers and their specified coding conventions. However, there may be an instance where iterative implementations might be slightly faster, especially owing to the fact that there is no function call overhead. Moreover, if a language uses tail call optimization, the programmer does not even have to do every recursive function to an iterative one manually: during compilation this can be automated easily.
Key Considerations and Error Handling
While seemingly straightforward, binary search has crucial aspects to consider:
- Sorted Array: Some algorithms are highly dependent on the fact that it is a sorted array and binary search falls under this category. This means that the behavior of this algorithm is undefined and it would take random steps, most of which would be useless when extracting the elements from an unsorted array.
- Error Handling: There are several crucial situations that are important to consider in the case when the target value is not present in the array. Additionally, the above search should return an appropriate error code or a special value of the absence of the target.
- Edge Cases: Depending on the implementation, it may be necessary to introduce separate conditions for treating empty arrays as well as arrays containing only one element.
That means Binary Search provides good performance benefits over the linear search specifically when dealing with big sizes of arrays. One is the use of divide-and-conquer strategy, which leads to a time complexity of O(log n) with the intention of eliminating unnecessary regions of the search space. Such comprehension enhances the developers’ abilities to select the most appropriate of the optimized modes of recursion and iteration, the mode that is most compatible with the programmer’s coding techniques. Also make sure that the array will be sorted before applying it and consider the error handling in your binary search implementation so that the binary search would be as strong and as adaptive to the various situations as possible.
Code Examples
Binary search without doubt is one of the most ideal methods of searching with sorted arrays. This is due to the fact that the method takes advantage of the sorted nature of the list of data, thus being able to reduce the amount of time required for the search as compared to when using linear search. Let’s go into details of explaining binary search both iteratively as well as recursively using Java and sample programs, comparisons, and use of binary search as well as other search algorithms.
The Binary Search Masterclass
It is like having a huge hall with books properly stacked on the shelves following the alphabetical order. The first and simplest method of searching for a book would be linear search, which involves going through each book starting from the first one until you find the title that you are looking for. Binary search on the other hand takes a much quicker approach in its manner of operation. The topic begins by analyzing the middle book. If it is the one which you have searched, then there it is, the word success! If not it eliminates half the library either the left or right half depending on the position of the middle book with reference to the target one. This process of narrowing the search space into relevant halves goes on until the target book is located or the left section of the shelves is empty indicating that the book cannot be found.
Translating into Java Code: Iterative Approach
Here's the iterative version of binary search in Java, where each step is explicitly controlled within a loop:
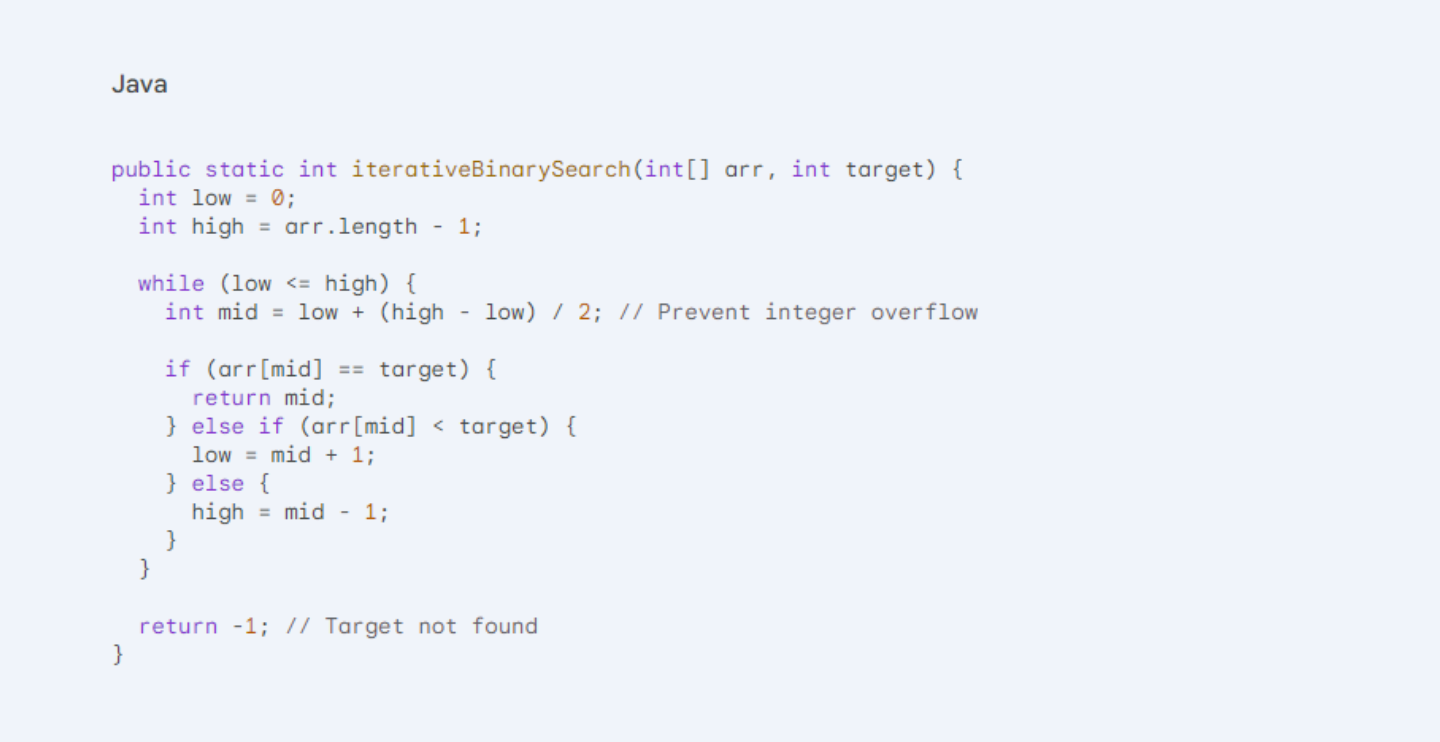
Explanation:
- We initialize low and high to represent the search boundaries (beginning and end of the array).
- A while loop iterates as long as low is less than or equal to high, indicating a non-empty search space.
- The mid index is calculated strategically to avoid integer overflow during large array searches.
- We compare the target with the element at mid:
- If they are equal, the target is found, and the function returns the mid index.
- If the target is greater, we eliminate the left half by setting low to mid + 1.
- If the target is smaller, we discard the right half by setting high to mid - 1.
- The loop continues until the target is found or low becomes greater than high, signifying an empty search space, in which case, the function returns -1.
Recursion: A Concise and Elegant Alternative
For those who favor a more concise approach, recursion offers a beautiful solution:
public static int recursiveBinarySearch(int[] arr, int target, int low, int high) {
if (low > high) {
return -1; // Target not found
}
int mid = low + (high - low) / 2;
if (arr[mid] == target) {
return mid;
} else if (arr[mid] < target) {
return recursiveBinarySearch(arr, target, mid + 1, high);
} else {
return recursiveBinarySearch(arr, target, low, mid - 1);
}
}Explanation:
- The function takes low, high, and target as arguments, along with the array itself.
- The base case checks if low is greater than high, indicating an empty search space, and returns -1.
- Similar to the iterative approach, mid is calculated.
- We compare the target with the element at mid:
- If they are equal, the target is found, and the function returns the mid index.
- Otherwise, recursive calls are made on either the left or right half of the search space depending on the target's position relative to mid.
Work from anywhere, get paid well: Apply for remote Java projects on Index.dev. Sign up now →
Performance Considerations
Iterative and Recursive implementations both have a time complexity of log n log n as compared to linear search best case of n. But still, as a rule, the iterative approach is smoother in terms of performance since calling functions in recursion implies certain overhead.
Iterative and recursive implementations can be interchangeable as a rule of thumb, and a programmer’s preference or coding style may sometimes dictate the choice. It could be explained by the fact that the iterative approach might be the better option in cases where maximum accuracy is of crucial importance.
Real-World Applications of the Binary Search Algorithm
In the world of big data, data processing has to be efficient at all times. In linear or sequential searching remember that when it comes to specific element searching in these large sets, linear search method is out of question. This is where the binary search algorithm comes in handy as a simple and effective search algorithm in sorted data structures.
At its essence, binary search utilizes what is called the ‘divide and conquer’ strategy; that is, since the data is sorted, the algorithm eliminates half of the search space after every exercise, which means that it is very efficient in terms of time complexity: O (log n). This means that they can perform the searches in the shortest time possible by using the algorithm even when dealing with a higher cardinality of millions or billions of elements in the dataset.
Here's a deeper dive into how binary search operates:
- Initialization: Selecting a single item from the set: We start with the entire set sorted from lower rank or value to higher rank or value.
- Comparison: The specific value in the array against which the target value is compared is the middle element.
- Match: If a match is located, the processing of the search is over.
- Smaller: If the target value is lower than the middle element, we continue our work with sorted lower half while the upper half is discarded.
- Greater: On the other hand, if the target value is higher than the loop current iteration value, we ignore half of the array and focus on the sorted half of the array.
- Iteration: On the remaining half of data, we again perform steps 1 and 2 on the data set, which in effect reduces the search space to half with each iteration.
- Termination: The search ends when the desired value is located or when all records have been examined (as the value is not present in the data set).
Now, let's explore some compelling real-world applications of binary search that showcase its practical value:
- Database Management Systems (DBMS): Data is stored and sorted in databases according to existing indexes which makes record search easier. Indexes are essential in ensuring quick search on data through the use of binary search techniques to help in speeding up manipulations on records and data queries.
- In-Memory Data Structures: Binary search becomes handy in applications that involve frequently accessing large existent datasets mapped to memory, such as stock tickers, and network routing tables. This characteristic has a logarithmic scalability level, which makes it possible for the performance to stay almost the same even with increasing data amount.
- Machine Learning and Artificial Intelligence (AI): A large number of algorithms used in the MLP computations require sorted datasets and data sets for training and classification. Binary search is another strong base for fast searching of these database arrays to find suitable training samples and to find suitable nearest neighbors for k-Nearest Neighbors (kNN) algorithms.
Beyond the Fundamentals
While the core binary search algorithm offers exceptional efficiency, there's room for further optimization in specific scenarios:
- Interpolation Search: This variant builds the possibility of estimating the position of the target element more accurately, which can potentially lead to decreasing the number of comparisons in some cases, taking advantage of the fact that the input data are sorted.
- Hybrid Approaches: When using the binary search and the use of hashing techniques incorporated, then it can be of great advantage if the data is not fully sorted but has some order into it. This can enhance further searches although increasing the number of queries per second may not be too efficient.
Binary search as a prominent algorithm for finding the required element in the data field occupies a significant position in computer science. Due to the fact that such an algorithm operates under logarithmic time complexity, this signifies that it is essential in handling big data across various fields. Whether it’s for organizing and cataloging vast amounts of data, designing AI algorithms, or implementing network security protocols, binary search allows for near-instantaneous information access and boosts the efficiency of the underlying systems. There are some more preliminaries for Big Data developers or scientists, such as search algorithms-seminal search like binary search would remain the key in the future.
Read more: 7 Best-Paying Tech Skills Companies Are Hiring for Now
Strengths and Weaknesses
Advantages of Binary Search Algorithm in Java
With regards to searching for and gathering pertinent information, Java provides a powerful set of search techniques. But as we are dealing with sorted arrays, binary search takes the trophy. This divide-and-conquer champion is highly praised for its efficiency and fastest in this run time, especially with large inputs. It’s time to turn to the world of binary search in Java and discover the top technical points and user-oriented applications of this method.
A binary search is the traditional algorithm widely used in interning and organizing the system or a computer program. However, binary search ultimately relies on the data being sorted, in order to be used. It carefully uses a combined division method whereby it divides the list by 2 recursively until it isolates the target element. Let us consider the existence of a large and well-organized library. It just means that binary search wouldn’t crawl through every book from every shelf with a lot of detail. It would instead choose the shelf with the highest probability by wisely picking the middle shelf and comparing the target book with the middle book on the shelf. If yes, then the quest is successfully finished. Otherwise it discards half of the library (symbolically) depending on whether it is less than or greater than the shelf number for a given target in the sorted shelves. This goes on and on dividing the space twice and recurs until the goal is located or if it is ascertained that the target is not available.
Java Implementation: This paper reveals the efficiency gains that can be realised in the above scenario as the difference between the ratio of actual to optimal throughput in each plant. It should be noted that binary search lends itself to efficient implementation in Java. Here's a glimpse into the code:
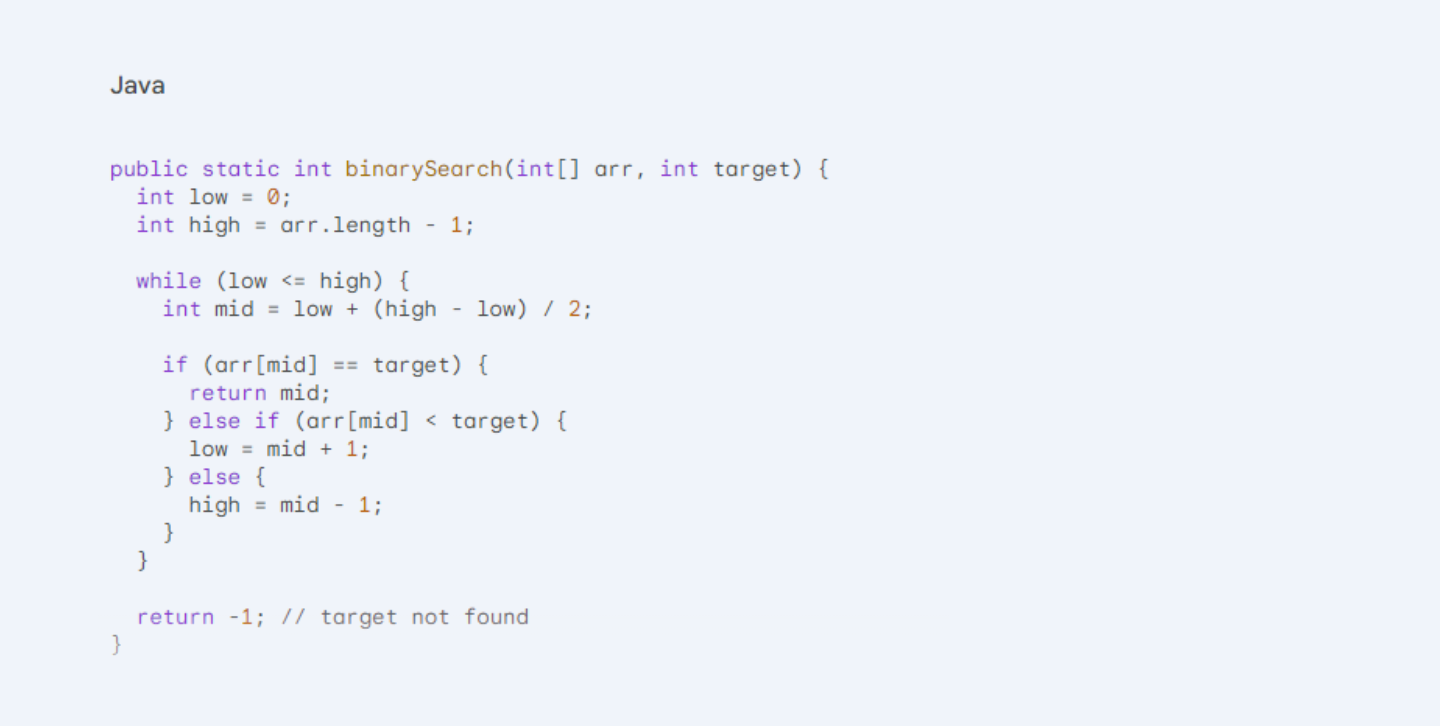
This code iterates through a loop, constantly halving the search space using the low and high indices. The crux lies in the calculation of the mid index. Here, Java's integer division (/) ensures we stay within the array bounds, avoiding potential out-of-bounds errors. The elegance lies in the fact that the number of comparisons required is logarithmic (base 2) to the array size, resulting in the coveted time complexity of O(log n). This is a significant improvement over linear search, whose complexity is O(n), which means the search time scales linearly with the data size.
Technical Advantages
Now, let's dissect the technical advantages that make binary search a champion in Java:
- Logarithmic Time Complexity (O(log n)): As evidenced earlier, the most important aspect is to find an algorithm or a method with the time complexity of logarithm. This translates to increased performance observed especially when working with large data sets. For example, using this approach for reaching a million-element array with the help of binary search takes about 20 comparisons while linear search takes a million.
- Space Efficiency: Binary search is unique in that it requires very sparse space compared to other sorting algorithms. This algorithm works on the primary sorted array without requiring any new data structure for holding on the results at intermediary stages. This makes it ideal for devices that have limited memory space for storing information on their local systems.
- Predictable Performance: Binary search has one of the great advantages of worst-case complexity amongst the comparison-based algorithms. Its operational characteristics concerning delivery time, for instance, are deterministic, unlike some probabilistic rating algorithms; therefore, it is well suited for real time systems where timely results are fundamental.
- Versatility: Binary search goes beyond simple element searches. It is used as a basis for other sophisticated and effective forms of algorithms such as interpolation search that fully capitalizes on the sorted nature of the data to make retrieval faster.
- Error Detection: One significant advantage of binary search is that it requires an array to be sorted thus it can detect errors in the data structure that have led to a change of order. When the target element is not found, then it most probably means there can be a sorting irregularity, which can help to identify irregularities of predetermined data.
- Beyond the Algorithm: There are also certain practical considerations that have an impact on the performance of a navigation policy, so it is quite natural that its implementation will depend on the evaluation of these factors by specific navigational institutions.
While binary search offers undeniable advantages, it's essential to consider practical factors:
- Applicability: Binary search is applicable only on ordered arrays Whereas Linear search can be used in both ordered and unordered lists. When organized in some manner, the organizing methodology leads to inability to serve all data in an efficient manner thereby increasing pre-sorting which sometimes leads to more overhead.
- Overhead: As simple as the above algorithm might seem, there is a certain amount of overhead involved when computing the midpoint, and then comparing values. This means that for large file sizes binary search outperforms linear search nevertheless for tiny files, linear search is preferable.
- Duplication Handling: In case the target element, which has been searched in the array, is in the array more than once, this search could only return the index of the first instance of the target element. Sometimes there could be a need to make changes to deal with duplicate entries In some cases there can be needed changes to manage duplicates.
Binary search is clear evidence of using algorithms as designed previously. And because of its logarithmic search time complexity, space complexity, and optimal potential as well as its applicability in numerous data retrieval operations, it is categorized as a core search tree.
Disadvantages of Binary Search Algorithm in Java
Binary search, one of the most basic yet essential algorithms of searching in computer science, is well aligned with Java since it is simple and works in logarithmic time, i.e., O(log n). But all the same, for a device for sorting, binary search is far from being a panacea. By appreciating some of these constraints, it is possible to make logical choices while choosing the right search algorithms while shooting Java apps.
Unsorted Data
The one thing that is mandatory about binary search is that the array in question has to be sorted. In Java, this is expressed in the context of an array in which the entries meet a prescribed order, whether numerical or lexicographic. Binary search unrelentingly capitalizes on this order; in each cycle, it narrows the number of elements to be sought to half. In its essence, it is based on constant positioning of objects in a given way that would enable a straightforward focusing on the target. This predictability is absent when working with random data, making binary search useless. In such cases, it is better to look for other algorithms, such as linear search (O(n) time complex) or hashing (iteration’s average time complexity of O(1)).
The Cost of Efficiency: Memory and Recursion
Despite the fact that binary search really excels in the aspect of time complexity, it often experiences time complexity overheads in terms of memory and control flow. The recursive implementation, most preferred in the Java programming language, makes use of the call stack. In very deep searches in thousands or millions of arrays, this stack usage can become massive, compounding to stack overflow. This can be a problem because it is hard to trust implementations that are so concise that it is possible to make small but subtle errors. Iterative implementations, while longer, can address this concern.
In addition, while comparing with modes like linear searching, binary searching requires extra memory space for checking variables in a form of mid-point indices. What is usually inconsequential because of rounding for small numbers yields a penalty when large numbers are involved, especially for extremely large arrays.
Caching Considerations and Error Prone Logic
Fixed element positioning is a problem in binary search as it makes the system vulnerable to cache problems. Within current generation CPU architectures, the use of multiple levels of caches to minimize memory latency. There are cases where the random access pattern of linear search might be more beneficial for CPU caching than inherent orderliness of binary search. Overall, the effect is not very big – however, it must be taken into account for cache-sensitive use-cases.
The question of selection of middle element and approach used in the binary search algorithm, especially with such variations as searching for one element in the sorted array containing duplicate values or absence of the search element requires careful consideration. Index calculations may be off by one, which is seemingly trivial, or there could be unnoticed mistakes in boundary conditions. Extra care must be taken when coding the algorithm and additional testing must be conducted to guarantee the algorithm works as intended with the binary search algorithm.
Limited Functionality: Beyond Simple Search
While the binary search can be quite efficient in searching for particular items, its usage is somewhat restricted when it comes to performing other types of search comparisons. For example, it cannot search the whole array to count all the array elements when they are in a given for loop or search for an element within a given range. In such cases, the simple linear search algorithms or other custom traversal techniques may be more applicable.
Despite the development of many new techniques, binary search is still one of the most effective algorithms that Java programmers can use. However, one can say that the efficiency of such an approach depends on a particular application. For sorted arrays, it is unbeatable and can help in carrying out several calculations in a much shorter time. However, it suffers from crucial disadvantages in handling unsorted data, tight memory overhead, and complicated code structures that require close attention to before using. At the same time knowledge of these trade-offs will help to make the correct decision and to choose the right search algorithm for the given problem.
Read more: Managing Payload and Response Without Java POJOs in Rest-Assured
Variations and Extensions
Binary search falls under the efficient searching algorithm family and its effectiveness is boosted by the “divide and conquer” principle. Binary search is particularly useful in sorted arrays but can be practically applied to various data structures that preserve sorted order. As seen, binary search is elegant in these structures, and it is for this reason that we need to unlock faster search operations.
Some data structures work with binary search relatively easily since arrays, where binary search naturally takes place, allocate memory in a continuous way. Let's delve into three prominent examples
Sorted Linked Lists
The dynamic resizing of linked lists provides the primary advantage for utilizing the data structure for frequently modified data. However, since these integers are not contiguous, it becomes a problem to have them involved in binary search. To this we can add that the middle element of an array cannot be accessed directly with some index.
Here's a possible approach:
- It helps in maintaining a node count during creation or insertion operation on a list.
- When searching for a target element, determine its likely position given the count and the position of a middle element.
- Complement the list with the depth first search by keeping track of visited nodes. Compare the Data of attained nodes with Target node if the count of visited nodes equals to the position specified in the target node.
This retains the time complexity of the binary search, namely logarithmic time (O(log n)) but we do have some overhead cost in terms of node count and traversal.
Balanced Search Trees
AVL trees and Red-Black trees, as well as few other trees, are inherently sored because of balancing. It also possesses the self- balancing property that makes it possible to search, insert, and delete in the tree effectively. For instance, the Entrez system, here, binary search transposes to the activity naturally.
We can implement a recursive approach that traverses the tree:
- Check whether the target element is equal to the current node’s data.
- In the event that the associate matches the criteria outlined by the search, then such a search is a success.
- On the other hand if the target element is smaller, move through the left subtree of the current node recursing through the tree.
- In case the target element is greater, travel to the right-subtree of the current node and perform a similar search there again.
Given that such trees maintain balance, the number of steps required to reach any node is approximately equal to log of the height, making the time complexity O(log n), as in case of basic binary search on arrays.
B-Trees
B-trees may be considered as a subclass of search tree which has been developed specially for a great amount of information which is stored on disk. They categorize data into nodes and their structure is described as a multi-tiered system. It may also be optimized to work at every level, or to navigate with some form of binary search.
Here's a simplified approach:
- Use the root node as the beginning reference point.
- To know the correct place to place the cursor or pointer during search, start with doing binary search in order to find out which child node may contain the element.
- Proceed as in the previous step of the recursive implementation: repeat the search of the item to be found at the lower levels of the tree, acting on the child nodes of the tree top level, and using a binary search.
- This is because each node in a B-tree contains a significant number of keys and pointers, which is located in the B-tree’s property of a hierarchical structure; it can provide high enough search performance O(log n) even for large-scale data sets.
Binary search doesn’t have to be used with arrays only. By knowing the basic understanding of sorting data and the independence of its algorithm to halve the search space, we can apply it across different sorted data structures. Depending on the types of operations that will be performed, additional actions related to the node count and traversal of sorted linked lists are needed, while for balanced search trees or B-trees, binary search is easily implemented as a part of these structures due to being inherently sorted and having a hierarchical architecture.
Therefore, there exists a potential application to expand the utilization of binary search beyond its original area of use, which enhances the use of binary search within the modern scenario of various data structures.
Advanced Concepts
The search algorithm that is acclaimed for its efficiency is the Binary Search Algorithm for sorted arrays. Its beauty is in approaching the problem of sorting in a manner that successively divides the list in two, iterating through comparing elements with the middle element. It has an astonishing time complexity of O(log n) and is much faster than linear search that has O(n) time complexity when working with huge data sets. However, all is not lost, for new opportunities can always be discovered! It is now time that we go through variations and optimizations specifically with respect to binary search in Java.
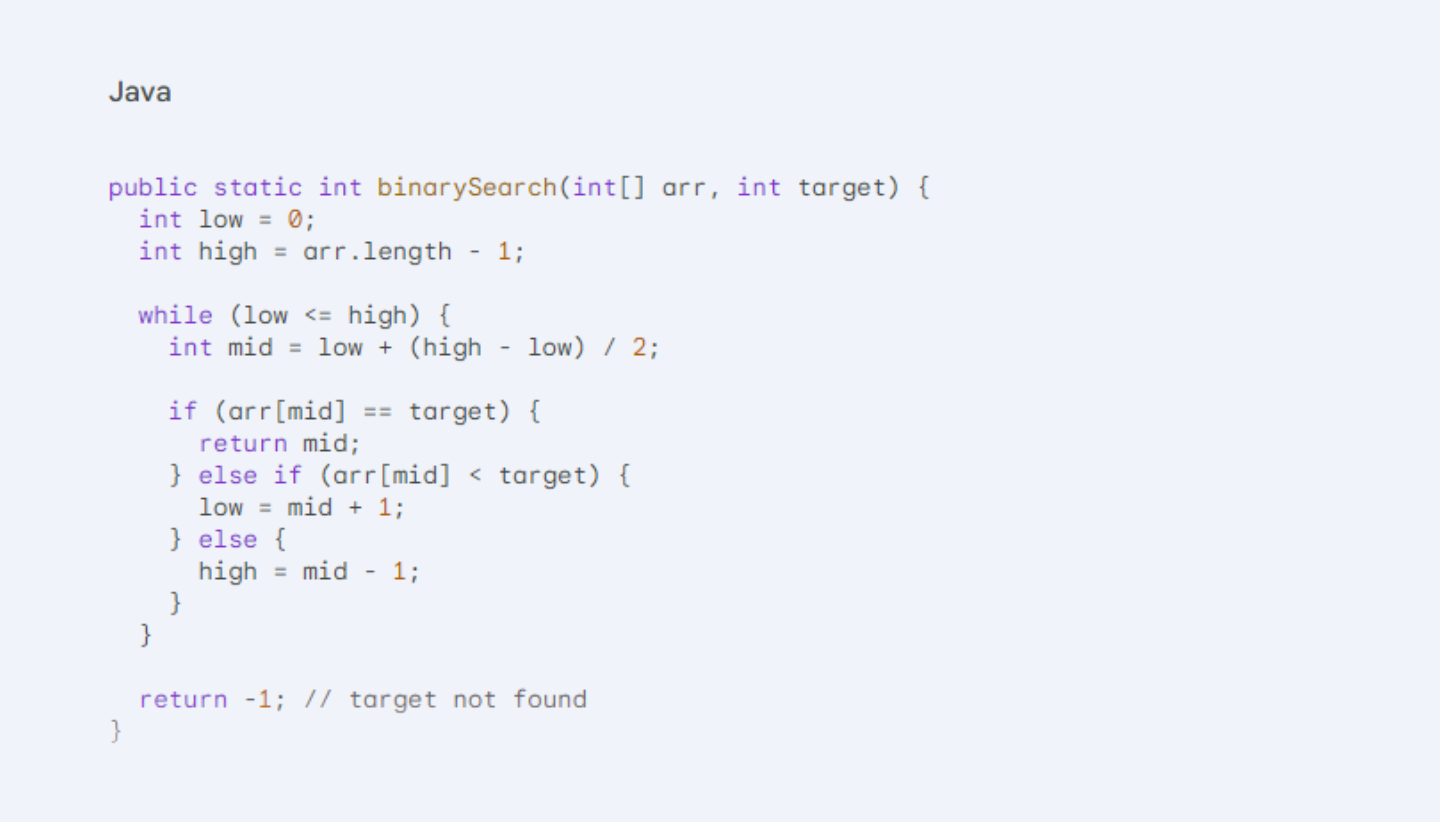
Classic Binary Search: The Foundation
The core binary search algorithm works as follows:
- Initialization: Define low and high indices representing the search boundaries (usually 0 and array length-1).
- Iteration: While low is less than or equal to high:
- Calculate the mid index as the average of low and high.
- Compare the target element with the array element at mid.
- If they are equal, the target element is found at index mid. Return mid.
- If the target element is less than the element at mid, update high to mid - 1 (search the left half).
- If the target element is greater than the element at mid, update low to mid + 1 (search the right half).
- Target Not Found: If the loop finishes without finding the target, it's not present in the array. Return -1 (or any appropriate indicator).
Here's a well-structured Java implementation:
Unveiling Binary Search Variations
While the classic approach focuses on finding an exact match, there are situations demanding more from our search:
- Finding the First Occurrence: This is especially useful where an element might have duplicates; so they only need the first index at which the item is found. If the target element is found in the middle then, begin searching in the left half for the first instance of the target element.
- Finding the Last Occurrence: Likewise, when there are duplicates, we may need to find the last occurrence’s index in the given array. There, in the course of the comparison stage, if the target element is found continue the search towards the right subarray.
- Finding Elements Around the Target: It is possible to use the construction of the binary search to determine elements that have other kinds of connections with the key. For instance, we can find the index of the element closest to the target (useful for sorted approximations) or the index of the element just greater than (or less than) the target (helpful for insertion points).
Applying some of these variations requires changing the nature of the comparison and update that occurs when the program loops.
Optimizing Binary Search for Performance
Here are some strategies to squeeze the most performance out of your binary search:
- Pre-sorted Arrays: Check that array to which keys will be sought is sorted before applying binary search. This means that sorting itself might take time or have other costs, but when there will be multiple queries on the same array, it is much faster to sort it in advance.
- Primitive Data Types: This is especially true if the data type calls to any of the Wrapper classes such as Integer or Long; for cases like int or long it may be advisable to use the primitive comparison instead of the Wrapper class methods like Integer. compare().
- Unrolled Loops: For such critical performance scenarios, one can use an optimization technique known as loop unrolling that involves manually coding a few iterations of the loop to get around these branch prediction penalties. That said, this approach can be as fast as lower-level programming languages while making code as hard to read as machine code and thus should be employed with a great deal of moderation.
- Iterative vs. Recursive: Nonetheless, the recursive approach is a more precise representation In terms of their execution, iterative solutions based on a cycle can be slightly faster due to the lack of open recursion calls.
- Hybrid Approaches: For very large use bit manipulations with binary search or any other data structures to search for example jump search.
Binary search proves to be deft at searching in the context of Java programming. When used with its nuanced caveats and specific kinds of tweaking in mind, keyword research can be a remarkably effective tool that helps to shape search strategies in a number of ways for particular purposes. Nevertheless, it is important to understand that depending on aspects like data size, access patterns and functionality it is important that the right course of action is taken. But where do you go from here? Fool around and try different variations and tailor your binary search implementations to achieve the best performance possible.
Read more: Top 6 Senior Java Developer Interview Questions and Answers
Common Mistakes and Pitfalls in Binary Search Algorithm in Java
Even though this algorithm could be characterized as quite simple, binary search can be considered a rather challenging algorithm to develop. It is difficult for a program to be bug-free no matter how experienced one is in java programming and yet one can get caught up in simple mistakes that may lead to the wrong result or behavior. This article does not only list possible errors and pitfalls in the program during the implementation of the binary search algorithm, but also offers information that would enable users to design an efficient and proper program.
1. Insidious Integer Overflow: HU and HLO Opening Lines = A Looming Threat
The first and the most deadly sin, it is possible to state, relates to the determination of the middle index of the search space. Now the idea of averaging (low + high) and dividing the result by two used in classical approach might produce wrong results due to the integer overflow, especially if the number of elements in the array is large. When low and high are both very large positive numbers, their sum might be greater than what an int variable in Java can contain, thus there will be an overflow and an incorrect middle index will be used.
To circumvent this issue, a safer approach is to use the following formula:

This expression performs the subtraction first, ensuring it doesn't overflow, and then adds the result to low to obtain the middle index.
2. Unsorted Arrays
Binary searching, as its name implies, relies on the basis that an order is present in the target array with elements arranged in increasing order. However, if the array is not sorted properly, then the algorithm becomes unmanageable and fails completely. The only thing that one has to make sure of is that the array being used is sorted before the use of binary search is done. There are some sorting algorithms used in Java like quicksorting or merge sorting that can be used for the effective sorting.
Advanced Insight: Standard binary search algorithm can be used for finding the least index for an element only, while changes are required to search for near-duplicate elements. It is easy to implement if you need to find any duplicate elements, the first or the last present, but if you need to compare the first and the last occurrence of a particular element, then checks around the middle index are required.
3. Off-by-One Errors
These seemingly minor errors can have significant consequences. A common mistake is using the wrong comparison operators (< instead of <=) when updating the search bounds (low and high). This can lead to infinite loops or incorrect handling of edge cases.
Pro Tip: Employ a loop invariant to reason about the state of low and high throughout the search process. This invariant should state that the target element lies within the subarray defined by low and high. Update the loop conditions and variable assignments meticulously to maintain this invariant and avoid off-by-one errors.
4. Not Handling the Target Not Found Scenario
Binary search provides an effective search method for elements inside a sorted array. However, one must also include another case that can be awkward if ignored – the case when the target element is not in the array. If the element to be searched is not found in the loop, a specific value such as -1 or some other exception can be used to inform the caller that the loop continues until the end of the array to return this result.
5. Recursive vs. Iterative Implementation: Choosing Wisely
Binary search can be implemented using both recursion and iteration. While recursion offers a concise and elegant approach, it can incur a slight overhead due to function call stack management. For performance-critical scenarios or when dealing with very deep recursion, an iterative implementation using a loop might be preferable.
Key Consideration: The choice between recursion and iteration often boils down to readability and maintainability. If the code clarity suffers in the pursuit of minor performance gains, a well-written recursive solution might be a better trade-off.
Calling Java Developers: Get top remote jobs with US, UK, and EU companies. Sign up at Index.dev!
In a Nutshell
Binary search can be defined as the type of search that is used when dealing with sorted arrays. Ensuring that the above guidelines of best practices for effective and efficient Java code and avoiding the common mistakes are observed will lead to good and performant Java code. By understanding binary search, you gain a powerful tool for tackling complex problems quickly and efficiently. Its divide-and-conquer approach is a fundamental concept in computer science and can be applied to various algorithms.
Read more: 10 Programming Languages that Will Land You a Salary of $100k in the US
Are you eager to advance your problem-solving skills to the next level? If you are a senior software developer interested in working remotely for high-end projects in the USA, UK, or Europe, register on Index.dev. Get matched with top companies on full-time, long-term engagements.
Struggling to find the right Java developer? We offer a global network of vetted Java developers, ready to join your team today. Hire faster, scale more easily!