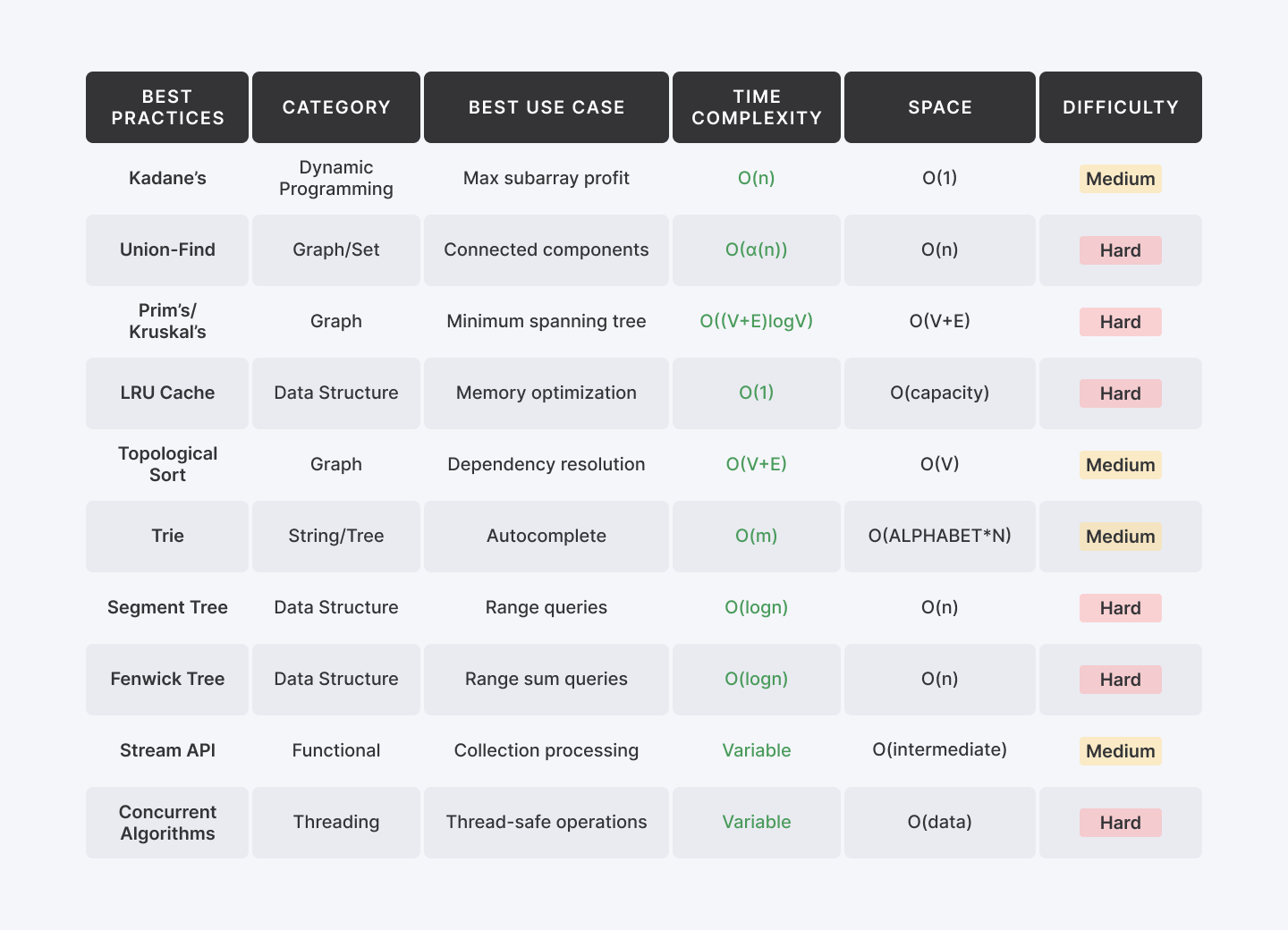
Most Java developers can write code. They know their syntax, inheritance, exception handling, Spring Boot. But they stop there, they never learn to see patterns.
According to the 2025 Stack Overflow Developer Survey, Java remains one of the five most-used languages globally. Engineers working in fintech, enterprise systems, and backend infrastructure use Java daily.
Developers who don’t know these 10 algorithms reach for brute force: nested loops, linear scans, checking every case. The code works… until the dataset explodes. Until production traffic hits and everything crawls.
In this guide, you’ll walk through 10 essential Java algorithms—what they do, how they work in code, and when to reach for each one.
Explore remote Java opportunities with Index.dev and land projects that match your skills and career goals.
1. Kadane's Algorithm
The maximum subarray problem seems academic until you realize it solves a real question: Given a series of values, what's the best contiguous window?
In finance, that window is the best time to hold a stock and sell for maximum profit. In trading systems, it's the most profitable trading period. In time-series analytics, it's the longest streak of growth.
Kadane's algorithm finds it in a single pass. O(n) time. O(1) space. Elegance.
How it works: Track two things as you iterate through the array. The maximum sum ending at the current position. The maximum sum seen so far. At each position, decide: extend the current window or start fresh.
Code implementation
public class KadaneAlgorithm {
public static int maxSubArray(int[] nums) {
int maxSum = Integer.MIN_VALUE;
int currentSum = 0;
for (int num : nums) {
currentSum = Math.max(num, currentSum + num);
maxSum = Math.max(maxSum, currentSum);
}
return maxSum;
}
}Why Java developers care
Financial systems built on Java constantly analyze price movements. Trading platforms need this. Portfolio analysis needs this. If you're optimizing for max profit over a time series, Kadane's is non-negotiable.
Real example: Stock prices [7, 1, 5, 3, 6, 4]. Buy at 1, sell at 6. Profit: 5. Kadane finds it without checking every combination.
2. Union-Find (Disjoint Set Union)
Social networks. Computer networks. Dependency graphs. Whenever you need to ask "are these two things connected?" Union-Find has the answer.
The algorithm maintains sets of elements and answers two questions fast:
Find: Which set does element X belong to?
Union: Merge two sets into one.
With path compression and union by rank optimizations, both operations run in nearly constant time: O(α(n)), where α is the inverse Ackermann function (it's practically instant, even with millions of items).
Code implementation
public class UnionFind {
private int[] parent;
private int[] rank;
public UnionFind(int size) {
parent = new int[size];
rank = new int[size];
for (int i = 0; i < size; i++) {
parent[i] = i;
}
}
public int find(int x) {
if (parent[x] != x) {
parent[x] = find(parent[x]); // Path compression
}
return parent[x];
}
public void union(int x, int y) {
int rootX = find(x);
int rootY = find(y);
if (rootX == rootY) return;
// Union by rank
if (rank[rootX] < rank[rootY]) {
parent[rootX] = rootY;
} else if (rank[rootX] > rank[rootY]) {
parent[rootY] = rootX;
} else {
parent[rootY] = rootX;
rank[rootX]++;
}
}
public boolean connected(int x, int y) {
return find(x) == find(y);
}
}Where it actually runs
Detecting cycles in graphs (critical for dependency management). Finding connected components in social networks. Building minimum spanning trees. Detecting fraud rings where transactions form suspicious patterns.
Your microservices form dependency chains. Service A → B → C. But D → A. That's a cycle. A production nightmare. Union-Find reveals these hidden cycles instantly.
Curious how clean architecture works in real Java projects? Dive into our DAO vs. DTO breakdown to see when (and why) each pattern matters.
3. Minimum Spanning Tree (MST) Algorithms
You have a set of cities (or servers, or data centers). You need to connect them all with minimum total distance (or cost). Prim's and Kruskal's algorithms both solve this, but they think differently.
Kruskal's Algorithm
Sort all edges by weight, then greedily add edges if they don't create a cycle (using Union-Find to detect cycles).
Code implementation
public class KruskalMST {
static class Edge implements Comparable<Edge> {
int u, v, weight;
public int compareTo(Edge other) {
return this.weight - other.weight;
}
}
public static void kruskal(int V, Edge[] edges) {
Arrays.sort(edges);
UnionFind uf = new UnionFind(V);
int totalCost = 0;
for (Edge edge : edges) {
if (!uf.connected(edge.u, edge.v)) {
uf.union(edge.u, edge.v);
totalCost += edge.weight;
System.out.println("Add edge: " + edge.u + " - " + edge.v);
}
}
}
}
Prim's Algorithm
Start with one vertex, then repeatedly add the cheapest edge that connects to the tree (using a priority queue to find it fast).
Code implementation
public class PrimMST {
public static void prim(int[][] graph, int V) {
boolean[] inMST = new boolean[V];
int[] key = new int[V];
Arrays.fill(key, Integer.MAX_VALUE);
PriorityQueue<Integer> pq = new PriorityQueue<>((a, b) -> key[a] - key[b]);
key[0] = 0;
pq.offer(0);
while (!pq.isEmpty()) {
int u = pq.poll();
if (inMST[u]) continue;
inMST[u] = true;
for (int v = 0; v < V; v++) {
if (graph[u][v] != 0 && !inMST[v] && graph[u][v] < key[v]) {
key[v] = graph[u][v];
pq.offer(v);
}
}
}
}
}When to use each
- Kruskal's:
- Sparse graphs where you have all edges upfront. Easier to reason about. Better for offline scenarios.
- Sparse graphs where you have all edges upfront. Easier to reason about. Better for offline scenarios.
- Prim's:
- Dense graphs where you're discovering neighbors as you go. Better for online network expansion.
- Dense graphs where you're discovering neighbors as you go. Better for online network expansion.
Real-world: Telecom companies use this to design fiber optic networks. Cloud infrastructure uses it to route traffic optimally. Any problem where you need to connect N points with minimum cost is MST.
4. LRU Cache
Cache miss. Evict the least recently used item. Add the new one. Repeat. Sounds simple. The trick is doing it in O(1) per operation.
The naive approach uses a LinkedList to track recency and a HashMap for access. But LinkedList operations are O(n). You need a DoublyLinkedList combined with HashMap to get O(1).
Why? HashMap gives O(1) access. DoublyLinkedList lets you move nodes in O(1) by holding references to them. Combined: O(1) per operation.
Code implementation
public class LRUCache<K, V> {
private final int capacity;
private final Map<K, Node<K, V>> map;
private final Node<K, V> head, tail;
static class Node<K, V> {
K key;
V value;
Node<K, V> prev, next;
Node(K key, V value) {
this.key = key;
this.value = value;
}
}
public LRUCache(int capacity) {
this.capacity = capacity;
this.map = new ConcurrentHashMap<>();
this.head = new Node<>(null, null);
this.tail = new Node<>(null, null);
head.next = tail;
tail.prev = head;
}
public V get(K key) {
Node<K, V> node = map.get(key);
if (node == null) return null;
moveToHead(node);
return node.value;
}
public void put(K key, V value) {
Node<K, V> node = map.get(key);
if (node != null) {
node.value = value;
moveToHead(node);
} else {
Node<K, V> newNode = new Node<>(key, value);
map.put(key, newNode);
addToHead(newNode);
if (map.size() > capacity) {
removeLRU();
}
}
}
private void moveToHead(Node<K, V> node) {
removeNode(node);
addToHead(node);
}
private void removeNode(Node<K, V> node) {
node.prev.next = node.next;
node.next.prev = node.prev;
}
private void addToHead(Node<K, V> node) {
node.next = head.next;
node.prev = head;
head.next.prev = node;
head.next = node;
}
private void removeLRU() {
Node<K, V> lru = tail.prev;
removeNode(lru);
map.remove(lru.key);
}
}Why it's critical
Every major cache system (Redis, Memcached concepts, database query caches) relies on this. If you're building a layer that can't fail when memory gets tight, LRU Cache is foundational.
Microsoft researchers found that proper cache eviction policies reduce cache misses by up to 40% compared to naive eviction. That's real impact on system performance.
Up next: Explore top algorithms across languages.
5. Topological Sort
Microservices. Build systems. Database migration scripts. Anytime you have tasks with dependencies, you need topological sort.
The algorithm arranges vertices in a linear order such that for every directed edge u→v, u comes before v. Only works on Directed Acyclic Graphs (DAGs).
DFS-Based Approach (most common)
Code implementation
public class TopologicalSort {
private List<Integer>[] graph;
private boolean[] visited;
private Stack<Integer> stack;
public void topoSort(int V, int[][] edges) {
graph = new ArrayList[V];
visited = new boolean[V];
stack = new Stack<>();
for (int i = 0; i < V; i++) {
graph[i] = new ArrayList<>();
}
for (int[] edge : edges) {
graph[edge[0]].add(edge[1]);
}
for (int i = 0; i < V; i++) {
if (!visited[i]) {
dfs(i);
}
}
while (!stack.isEmpty()) {
System.out.print(stack.pop() + " ");
}
}
private void dfs(int u) {
visited[u] = true;
for (int v : graph[u]) {
if (!visited[v]) {
dfs(v);
}
}
stack.push(u);
}
}
Kahn's Algorithm (BFS-based, easier to visualize)
Code implementation
public class KahnAlgorithm {
public static List<Integer> topoSort(int V, int[][] edges) {
int[] inDegree = new int[V];
List<Integer>[] graph = new ArrayList[V];
for (int i = 0; i < V; i++) {
graph[i] = new ArrayList<>();
}
for (int[] edge : edges) {
graph[edge[0]].add(edge[1]);
inDegree[edge[1]]++;
}
Queue<Integer> queue = new LinkedList<>();
for (int i = 0; i < V; i++) {
if (inDegree[i] == 0) {
queue.offer(i);
}
}
List<Integer> result = new ArrayList<>();
while (!queue.isEmpty()) {
int u = queue.poll();
result.add(u);
for (int v : graph[u]) {
inDegree[v]--;
if (inDegree[v] == 0) {
queue.offer(v);
}
}
}
return result;
}
}Production use
Deploy services in the correct order. Resolve npm/maven dependencies. Execute SQL migrations in dependency order. Build systems like Gradle use topological sort to determine which tasks can run in parallel.
If you're building a microservice orchestrator or a build system, this is essential.
6. Trie
You type three letters and 50,000 suggestions appear instantly. That's a Trie.
A Trie stores strings in a tree where each node represents a character. Common prefixes share nodes. Searching for all words with the prefix "ama" means traversing to the 'm' node and collecting everything below it.
Code implementation
public class TrieNode {
Map<Character, TrieNode> children = new HashMap<>();
boolean isEndOfWord = false;
String word;
}
public class Trie {
TrieNode root = new TrieNode();
public void insert(String word) {
TrieNode node = root;
for (char c : word.toCharArray()) {
node.children.putIfAbsent(c, new TrieNode());
node = node.children.get(c);
}
node.isEndOfWord = true;
node.word = word;
}
public List<String> autocomplete(String prefix) {
TrieNode node = root;
for (char c : prefix.toCharArray()) {
if (!node.children.containsKey(c)) {
return new ArrayList<>();
}
node = node.children.get(c);
}
List<String> results = new ArrayList<>();
dfsCollect(node, results);
return results;
}
private void dfsCollect(TrieNode node, List<String> results) {
if (node.isEndOfWord) {
results.add(node.word);
}
for (TrieNode child : node.children.values()) {
dfsCollect(child, results);
}
}
}Time complexity
Insert and search both O(m) where m is the length of the word. Finding all suggestions with a prefix is O(n) where n is the number of nodes in the subtree (still efficient because you're not checking the entire dictionary).
Where it runs
Search engines. IDE autocomplete. Dictionary applications. Spell checkers.
Building a Trie is straightforward. The optimization challenge comes with large vocabularies and memory constraints. Some systems use compressed Tries (like radix trees) to save space.
7. Stream API
Java 8 introduced Streams—a functional way to transform collections. Not for every use case, but when you're filtering, mapping, or aggregating data, Streams are elegant and often efficient.
You have a list of 100,000 transactions. You need to:
- Filter: Only transactions > $10,000
- Filter: Only completed transactions
- Transform: Extract ID and amount
- Sort: Highest amount first
- Limit: Top 100
- Collect: Return as list
Imperative approach (what most Java developers write)
List<Transaction> highValueTransactions = new ArrayList<>();
for (Transaction t : transactions) {
if (t.getAmount() > 10000 && t.getStatus() == Status.COMPLETED) {
TransactionSummary summary = new TransactionSummary(t.getId(), t.getAmount());
// Manual sort tracking (painful)
// Manual limit check (painful)
highValueTransactions.add(summary);
}
}
Collections.sort(highValueTransactions, (a, b) -> Double.compare(b.getAmount(), a.getAmount()));
highValueTransactions = highValueTransactions.subList(0, Math.min(100, highValueTransactions.size()));Functional approach (Stream API)
List<Transaction> highValueTransactions = transactions.stream()
.filter(t -> t.getAmount() > 10000)
.filter(t -> t.getStatus() == Status.COMPLETED)
.map(t -> new TransactionSummary(t.getId(), t.getAmount()))
.sorted(Comparator.comparingDouble(TransactionSummary::getAmount).reversed())
.limit(100)
.collect(Collectors.toList());Why Streams win
✓ Intent is crystal clear: "filter → transform → sort → limit → collect"
✓ Reads like English, not mechanical steps
✓ Each operation is a distinct transformation
✓ Less code = fewer bugs
✓ Parallelizable: Change .stream() to .parallelStream() for multi-threaded execution
Grouping and Aggregation
Without Streams: 15 lines of manual iteration + map management
With Streams: One declarative line
Map<String, Double> totalByClient = transactions.stream()
.collect(Collectors.groupingBy(
Transaction::getClientId,
Collectors.summingDouble(Transaction::getAmount)
));The Caveat: Streams create intermediate objects. For tight loops processing millions of records (1M+ items), sometimes imperative loops are 10-20% faster due to object allocation overhead. But the clarity gain is usually worth it.
When to use Streams
✓ Filtering + mapping + sorting pipelines
✓ Grouping and aggregations
✓ Code clarity matters more than microsecond optimizations
✓ Dataset < 10M items
When NOT to use Streams
✗ Tight loops > 1M items where latency is critical
✗ Modifying state during iteration
✗ Breaking early from complex conditions
Real example
E-commerce platform processing orders. Streams make it trivial to filter by region, map to profit, group by customer, and calculate totals. Manual loops would be 3x longer.
8. Concurrent Algorithms
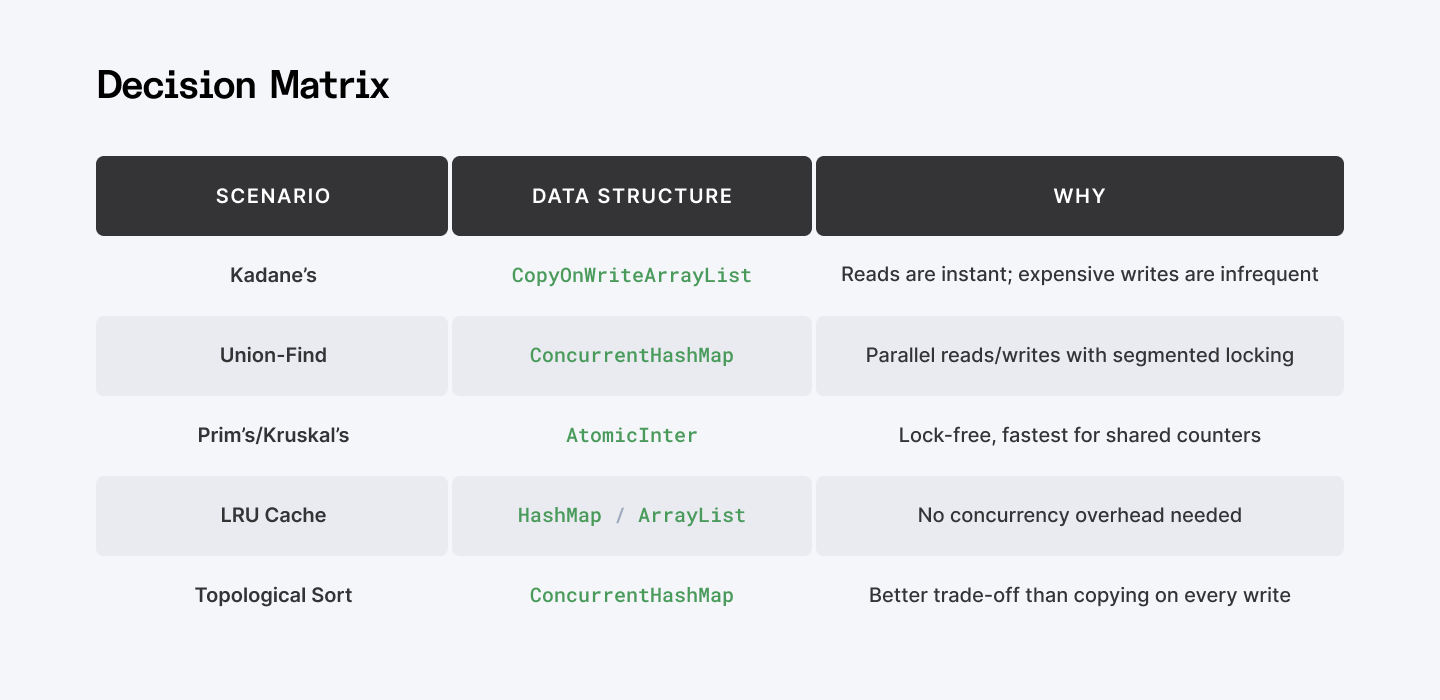
Multiple threads accessing shared data. Race conditions everywhere. Deadlocks waiting to happen. The answer isn't just synchronized blocks—it’s choosing the right concurrent data structure for the workload.
The problem is simple
This looks innocent, but it’s not thread-safe:
Map<String, Integer> counters = new HashMap<>();
counters.put("requests", 0);
// Multiple threads do:
counters.put("requests", counters.get("requests") + 1); // NOT ATOMICA regular HashMap plus get() then put() is not atomic. Two threads reading the same value and writing back at the same time will lose updates. You think you incremented a counter twice; the map shows 1 instead of 2.
The solution: pick the right tool for the access pattern.
ConcurrentHashMap
Use when lots of threads read/write different keys (session cache, per-user counters, rate limiting). Multiple threads can write to different segments simultaneously.
How it works: Internally sharded; threads updating different buckets can proceed in parallel.
Code implementation
Map<String, AtomicInteger> counters = new ConcurrentHashMap<>();
// Thread A
counters.computeIfAbsent("user_1", k -> new AtomicInteger(0))
.incrementAndGet();
// Thread B (at the same time)
counters.computeIfAbsent("user_2", k -> new AtomicInteger(0))
.incrementAndGet();- Reads: O(1), rarely blocked.
- Writes: O(1), contention only on same key/bucket.
- Best when: thousands of threads, high write volume spread across keys.
AtomicInteger / AtomicLong
Use when you just need a few shared numbers (global request count, in‑flight operations).
How it works: Uses lock‑free CAS (Compare‑And‑Swap) at the CPU level.
Code implementation
AtomicInteger requestCount = new AtomicInteger(0);
requestCount.incrementAndGet(); // atomic ++
requestCount.addAndGet(5); // atomic += 5
requestCount.compareAndSet(5, 10); // if ==5 then set to 10- Operations: O(1), lock‑free.
- Best when: many threads updating one counter.
CopyOnWriteArrayList
Use when reads dominate writes (e.g., listener lists, feature flags, permissions).
How it works: Every write copies the underlying array, so reads are lock‑free and always see a consistent snapshot.
Code implementation
List<String> listeners = new CopyOnWriteArrayList<>();
listeners.add("listener1"); // Expensive: copies array
listeners.add("listener2"); // Expensive again
for (String l : listeners) { // Cheap: no locks while iterating
notifyListener(l);
}- Reads: O(1), zero contention.
- Writes: O(n), copies the whole array.
- Best when: millions of reads, rare writes.
The key insight
Wrong choice = bottleneck. Right choice = 10x performance.
- Plain HashMap + synchronized → one thread holds the lock, everyone waits.
- ConcurrentHashMap → threads updating different keys proceed in parallel.
- CopyOnWriteArrayList in a write‑heavy path → every write copies the whole list. Disaster.
The real skill isn’t just knowing these classes. It’s recognizing your workload pattern and picking the structure that fits.
9. Segment Tree
You have an array of stock prices. Someone asks: "What's the minimum price between day 10 and day 45?" Easy—iterate and find it. But then they ask 10,000 more questions like that, and simultaneously the prices update. Now you have a real problem.
Naive approach: O(n) per query, O(1) per update. Terrible when queries outnumber updates.
Segment Tree fixes this: O(log n) per query, O(log n) per update. Build it once, then answer thousands of queries fast.
How it works: Build a binary tree where each node represents a range. The root covers the entire array. Each internal node covers half of its parent's range. Leaf nodes are individual elements.
When you query a range, you navigate the tree and combine results from nodes that fall entirely within your query range. When you update an element, you update that leaf and propagate changes up the tree.
Code implementation of the core logic
public class SegmentTree {
private int[] tree;
private int n;
public SegmentTree(int[] arr) {
this.n = arr.length;
this.tree = new int[4 * n];
build(arr, 0, 0, n - 1);
}
// Query sum in range [l, r]
public int query(int l, int r) {
return query(0, 0, n - 1, l, r);
}
// Update element at index idx to val
public void update(int idx, int val) {
update(0, 0, n - 1, idx, val);
}
}Note: For a full reference implementation with build(), recursive query(), and update(), you can explore this open-source Java Segment Tree on GitHub. Full Segment Tree implementation in Java (GitHub). The key is understanding the concept: tree nodes store range aggregates (sum/min/max), and both operations navigate down in O(log n).
Why Segment Trees matter
Financial systems query historical price ranges constantly. Risk analytics platforms need minimum/maximum exposure over time windows. Database systems use segment trees for fast range aggregations.
Time:
- Build: O(n)
- Query: O(log n)
- Update: O(log n)
Space Complexity: O(4n) - the tree needs up to 4 times the original array size in worst case.
The flexibility: You can adapt segment trees for any associative operation—sum, min, max, XOR, GCD—by changing the combine function. Need range minimum and range updates? Segment trees support lazy propagation for that too.
Example usage (conceptual):
- Prices = `[3, 2, 8, 6, 1, 4, 7, 5]`
- Query sum [2, 5] → `8 + 6 + 1 + 4 = 19`
- Update index 3 from 6 to 10
- Query sum [2, 5] again → `8 + 10 + 1 + 4 = 23`
- Range minimum [2, 5] with RMQ version → `1`

10. Fenwick Tree (Binary Indexed Tree)
Segment Trees are powerful but complex. Sometimes you only need range sum queries and point updates. Fenwick Tree delivers exactly that in a fraction of the code.
A Fenwick Tree uses clever bit manipulation to achieve O(log n) operations. Instead of building a balanced tree structure, it stores partial sums in an array where the index tells you which range each element covers.
The magic: Use the least significant bit (LSB) to determine responsibility. Index 12 (binary 1100) is responsible for the sum of 4 elements. Index 6 (binary 110) is responsible for 2 elements. This creates a cascading responsibility hierarchy without explicitly building a tree.
Code implementation of the core logic
public class FenwickTree {
private int[] tree;
private int n;
public void update(int idx, int delta) {
while (idx <= n) {
tree[idx] += delta;
idx += idx & (-idx); // Add last set bit
}
}
public int prefixSum(int idx) {
int sum = 0;
while (idx > 0) {
sum += tree[idx];
idx -= idx & (-idx); // Remove last set bit
}
return sum;
}
}That's it. The bit operation (idx & (-idx)) isolates the least significant bit (LSB) and determines which range this index manages. Two functions. O(log n) each. Done.
Note: For a complete Java Fenwick Tree with range/query variations, see this implementation: FenwickTree.java – TheAlgorithms/Java (GitHub)
Why Fenwick Trees are elegant
In competitive programming and interview settings, Fenwick Trees are gold because
- Tiny code footprint - implement in under 20 lines for basic cases
- Fast in practice - the constant factors are tiny (just bit operations)
- Memory efficient - O(n) exactly, no wasted space like Segment Trees
- Only for prefix/range sums - specialized but lightning fast for that use case
Time Complexity:
- Build: O(n log n)
- Point Update: O(log n)
- Prefix Sum: O(log n)
- Range Sum: O(log n)
Space Complexity: O(n)
When to use: Stock price cumulative analysis. Inversion count problems. Any scenario where you need to query prefix sums billions of times while updating values.
Want to test your real Java skills? Try these 25 challenges and compare your approach with the solutions.
Tying It All Together: When to Use What
You now have 10 algorithms that solve 80% of Java programming problems. The real skill isn't knowing them—it's recognizing which problem you have.
- Financial/Optimization problems? Kadane's.
- Detecting connections/cycles? Union-Find.
- Connecting with minimum cost? MST (Prim's or Kruskal's).
- Memory management? LRU Cache.
- Task dependencies? Topological Sort.
- Text searching? Trie.
- Range queries? Segment Tree or Fenwick Tree.
- Processing collections? Stream API.
- Concurrent access? Concurrent data structures.

According to Microsoft's research on enterprise systems, developers who knew algorithm selection patterns were 3-5x more effective at optimizing codebases.
Your Next Move
Pick one algorithm. Implement it in a blank file. No copy‑paste, no templates. Type it out, break it, fix it, and make sure you understand every line.
Then put it under pressure. Solve a LeetCode or HackerRank problem that forces you to use it. Then another. Then another. By the time you’ve solved 20 problems across these 10 algorithms, you’re no longer asking “what’s the algorithm?”—you’re thinking “I’ve seen this shape before.”
That’s the inflection point. From there, you stop brute‑forcing your way through code and start recognizing patterns. You don’t just write programs that work; you design systems that hold up under real traffic, real data, real users.
➡︎ Want to grow from “writing code” to truly understanding it? Join Index.dev and get matched with global projects that value strong Java fundamentals, performance thinking, and algorithmic problem-solving.
➡︎ Want to level up your Java expertise and algorithm knowledge? Dive deeper into practical implementation guides and career growth strategies. Explore how to retrieve index values from maps in Java for cleaner code, discover binary search algorithm implementations with working examples, and understand the complete software engineer skills roadmap. If you're advancing your career, check out how to become a senior software engineer with the right skills and salary insights, or learn proven strategies for leading teams of senior developers effectively. Curious about hiring? See the latest cost breakdowns for hiring Java developers across CEE, LATAM, and Asia in 2025, and explore our complete guide to the top 11 key algorithms developers should master. Browse our full collection of Java development and career advancement articles for more expert insights from Index.dev.
