Open-source AI didn't knock on the door politely in 2025. It kicked the door down, released five frontier-class models under permissive licenses, proved reasoning doesn't require closed walls, and made half the industry's playbook obsolete.
While ChatGPT still commands 180+ million users, on-premises solutions now control over half the entire LLM market—and that share is accelerating.
This guide cuts through industry spin. We tracked the releases that actually mattered, the architectural shifts that rewired infrastructure, and the moments where proprietary vendors realized they couldn't compete on price, speed, or openness anymore. What follows are the 10 updates that fundamentally changed how developers build AI systems.
Building AI on open models? Index.dev helps you hire senior AI and ML engineers who know how to deploy, scale, and secure open-source AI in production.
Quick Reference for Model Selection
Model | Total Params | Active Params | License | Best For | Deployment | Key Trade-off |
DeepSeek R1 | 671B | 37B | MIT | Reasoning, Math, Code | Local / API | Chinese geopolitical concerns |
Llama 4 | 405B+ | - | Llama Comm. | General + Vision | Your Cloud | EU licensing restrictions |
Qwen 3 | 235B | - | Apache 2.0 | Multilingual, Global | Anywhere | Less Western dev community |
Mistral Large 3 | 675B | 41B | Apache 2.0 | Frontier Reasoning | Any Scale | Slightly slower inference |
OpenAI gpt-oss | 120B / 20B | - | Apache 2.0 | Agentic, Tool-use | Production | API cannibalization risk |
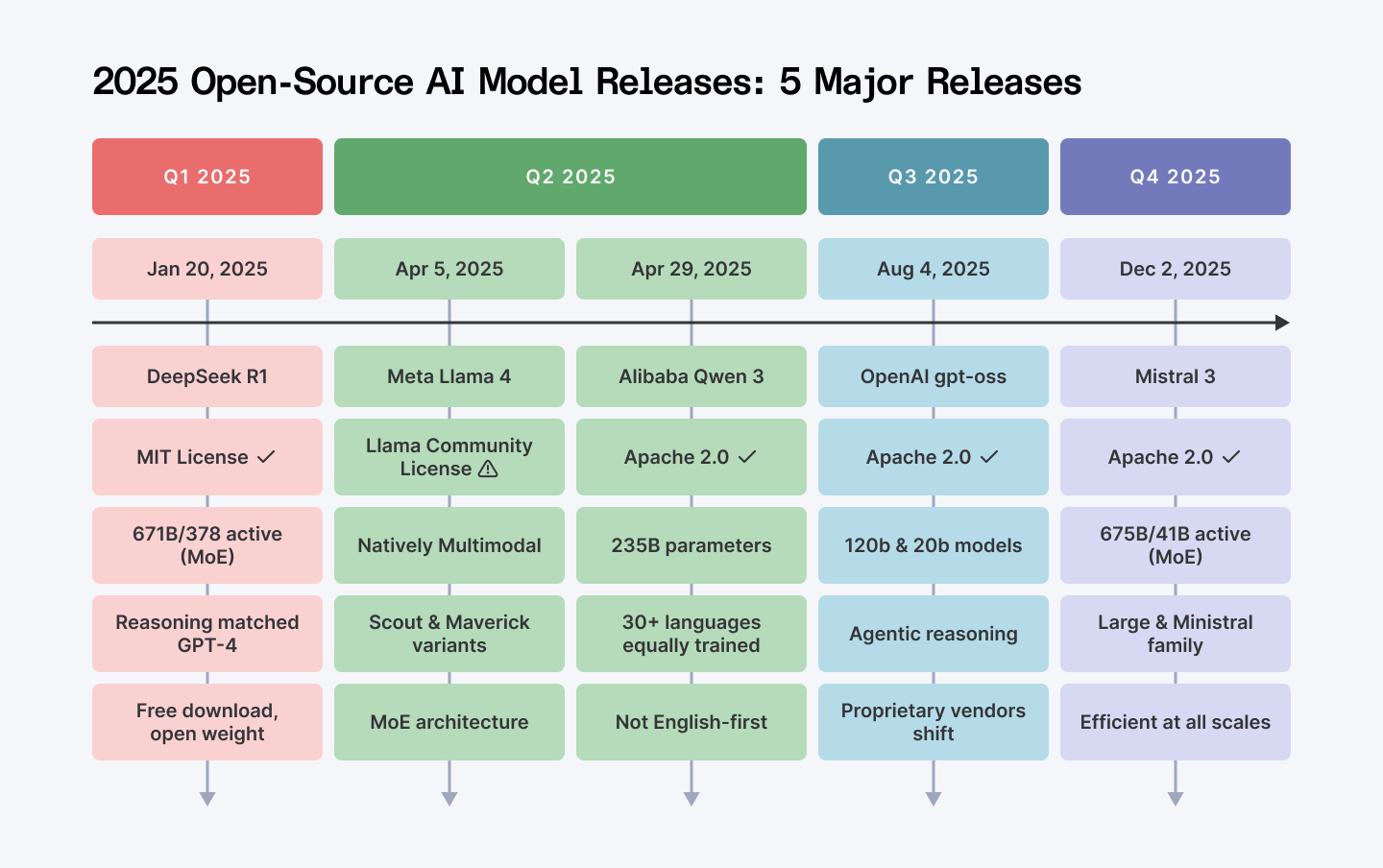
The 2025 open-source explosion
1. DeepSeek R1
January 20, 2025
DeepSeek announced R1. MIT license. Open weights. 671 billion parameters total with 37 billion active through mixture-of-experts architecture.
Reasoning performance that matched GPT-4 on benchmarks. And you could download it in January.
Before R1, reasoning models felt proprietary. You paid-per-token or you went without. That was the deal. R1 broke that deal completely.
Why this matters
You can now download weights, run locally, fine-tune on your proprietary data, deploy offline. No API dependency. No token meter. No vendor lock-in. The cost math changed overnight—and OpenAI's playbook became obsolete.
Deploy via Ollama (30 seconds), use Together AI for inference, or integrate with LangChain for RAG pipelines.
The tooling matured faster than anyone predicted.
The ripple effect
R1 unlocked something deeper. Chinese labs—Alibaba, ByteDance, Tencent—suddenly started releasing their best models.
According to Interconnects' 2025 review, this single release redefined what "open" meant in AI. Proprietary vendors realized they couldn't gatekeep reasoning anymore. So they started copying the open-source playbook.
Wondering if DeepSeek is safe to use in production? This article unpacks the real privacy and security risks you need to know.
2. Llama 4
April 5, 2025
Meta shipped Llama 4 in two flavors: Scout and Maverick. Both natively multimodal.
"Natively" isn't marketing fluff here. These aren't image encoders bolted onto a text model. Vision, video, and text process in the same forward pass.
The architecture shifted to mixture-of-experts (MoE), meaning fewer parameters activate per token. Faster inference. Lower memory. More efficient than anything the proprietary crowd shipped.
Here's the licensing move that matters
Llama 4 uses Meta's Llama Community License, which explicitly restricts EU deployment and applications exceeding 700 million monthly active users.
This isn't open-source by OSI definition. It's strategic. Meta is saying: "You get the weights. You handle the compute. You own the compliance nightmare. We avoid liability."
That's smart architecture. And it signals something important: even closed-model vendors realized self-hosted deployment is the future.
For teams outside the EU
Llama 4 is production-ready today. Available on Hugging Face. Download weights. Deploy in your cloud. Own your infrastructure.
3. Qwen 3
April 29, 2025
Most "multilingual" models are English-first with translations bolted on like a suspicious addon. They're embarrassing.
Qwen 3, at 235 billion parameters, trained equally on 30+ languages. Japanese. Hindi. Korean. Mandarin. Not an afterthought. Not worse performance. Genuinely comparable depth across the board.
Then Alibaba released it under Apache 2.0 and barely mentioned it. Western developer press didn't notice for three months.
For teams building outside the US
This is your foundation model. Not someday. Now.
Specialized variants came next: Qwen2.5-Math for reasoning, Qwen2.5-Coder for software engineering. You don't retrain from scratch anymore. You fine-tune from these.
Market signal
Qwen has overtaken Llama in total downloads and is now the most-used base model for fine-tuning. This didn't happen because of benchmarks. It happened because developers use what works for their use cases, and Qwen works everywhere.
Curious how Qwen stacks up for real-world coding? We broke down the best Qwen models, benchmarks, and where they shine.
4. Mistral 3
December 2, 2025
Mistral shipped two things: ambition and pragmatism.
Mistral Large 3 is a sparse 41-billion-active model with 675 billion total parameters. It handles frontier reasoning tasks.
Then Mistral released Ministral 3—3B, 8B, 14B variants for the rest of us. Models that run on single GPUs. Laptops. Edge devices. No cloud fees. All under Apache 2.0.
Bonus
Devstral 2, Mistral's coding-specialized model, hits 72.2% on SWE-bench Verified—state-of-the-art for open-source code agents. If you're building software engineering automation, this is your baseline now.
Deployment reality
Ministral 3 runs offline. Fine-tune locally. Deploy in regulated environments.
No data leaves your infrastructure. This matters more than benchmark numbers when you're dealing with HIPAA, GDPR, or financial compliance.
5. OpenAI Releases gpt-oss
August, 2025
OpenAI released gpt-oss-120b and gpt-oss-20b under Apache 2.0. Let that sink in. The company that built a $150 billion business on proprietary models just went open-source.
Not because they're generous. Because they realized something fundamental: you can't monopolize the entire stack. The open-source ecosystem won't let you.
This was the watershed moment for the proprietarily-minded.
These aren't research artifacts. They're reasoning models optimized for agentic workflows, tool-use, and few-shot function calling. Inference-time scaling. Cost-effective reasoning. Built for the future they see coming.
What it signals
OpenAI's move reveals a structural shift in competitive dynamics. Proprietary frontiers still exist (GPT-4o, o1). But baseline reasoning? That's a commodity now. Better to own the research, distribute the inference, and compete on polish.
ChatGPT is everywhere, but how are people really using it at scale? Dive into the latest usage stats and surprising patterns behind 800M users.
6. Docling
January, 2025
IBM open-sourced Docling, and it hit 10,000 GitHub stars in under a month.
Here's what that means
Every developer working on RAG systems has been waiting for this.
Docling is a toolkit for parsing PDFs, Word docs, and images into structured formats that RAG systems can actually ingest.
Not OCR theater. Not fragile regex. Layout-aware parsing with metadata extraction.
Why this matters so much
RAG systems fail downstream when document ingestion fails. Wrong chunking destroys context. Lost structure kills citations. Hallucinated references make your system unreliable.
Docling reduces downstream hallucinations by roughly 20% because the documents feeding your LLM are clean.
MIT licensed. Works with LangChain, LlamaIndex, and LLaMA-Factory.
Real deployment
You have 500 PDFs of product documentation. Parse with Docling. Chunk intelligently. Embed. Search. Your RAG system's retrieval accuracy improves immediately. This isn't theoretical. This is what teams are doing right now.
The exponential growth in open-source releases is real.
1,000-2,000 models uploaded daily in late 2025. That's 30,000-60,000 per month. The open-source ecosystem didn't just accelerate. It went hyperbolic.
7. LangChain's LangGraph
2025 Updates
LangChain shipped LangGraph—an execution engine for multi-agent workflows. Traditional chains collapse the moment things get complex. Agent A calls Tool B. Tool B fails. Now what? Retry? Fallback? Ask Agent C? You're stuck. The entire flow breaks.
LangGraph doesn't break. You define state machines. Agents route through based on outcomes. Error handling, retries, conditional logic—these are first-class citizens, not afterthoughts.
Performance
35% faster retrieval accuracy compared to 2024 versions. Real benchmarks from real production systems.
This matters because production RAG systems need robustness. One failed retrieval shouldn't cascade into system failure. LangGraph fixes that fundamental problem.
8. LlamaIndex's Multi-Document Agents
2025 Updates
LlamaIndex added reasoning across multiple unrelated document collections simultaneously.
Scenario
You have 500 PDFs in Product, 300 in Legal, 200 in Engineering. LlamaIndex now reasons across all three in one query. Maintains context. Doesn't hallucinate. Doesn't lose coherence.
Technical improvements
Advanced chunking strategies, hybrid search (semantic + keyword retrieval), context-aware filtering.
Results
Retrieval accuracy hit 92% in benchmarks—matching closed-source RAG systems from 2024. The open-source baseline caught up. Then it kept going.
Deployment
Run locally, on Hugging Face Spaces, or on your cloud. Same code everywhere.
9. Hugging Face Enterprise Hub 2.0
2025 Launch
Hugging Face isn't just a model zoo anymore. They built an actual production platform.
Serverless Inference Functions
Click a button. Deploy a model as an auto-scaling API endpoint. One-click integration with AWS SageMaker, Google Cloud Vertex AI, Azure ML.
You don't write infrastructure code anymore.
What this changed
You train in Hugging Face Spaces. Deploy with one click. Weeks of infrastructure work becomes minutes.
Impact on teams
The barrier between research and production collapsed. Small teams without DevOps infrastructure now ship agentic workflows to production. That's not a feature. That's a paradigm shift.
10. Vector Databases Mature
2025 Landscape
Vector databases stopped being specialized tools. They became what they should've been five years ago: commodity infrastructure.
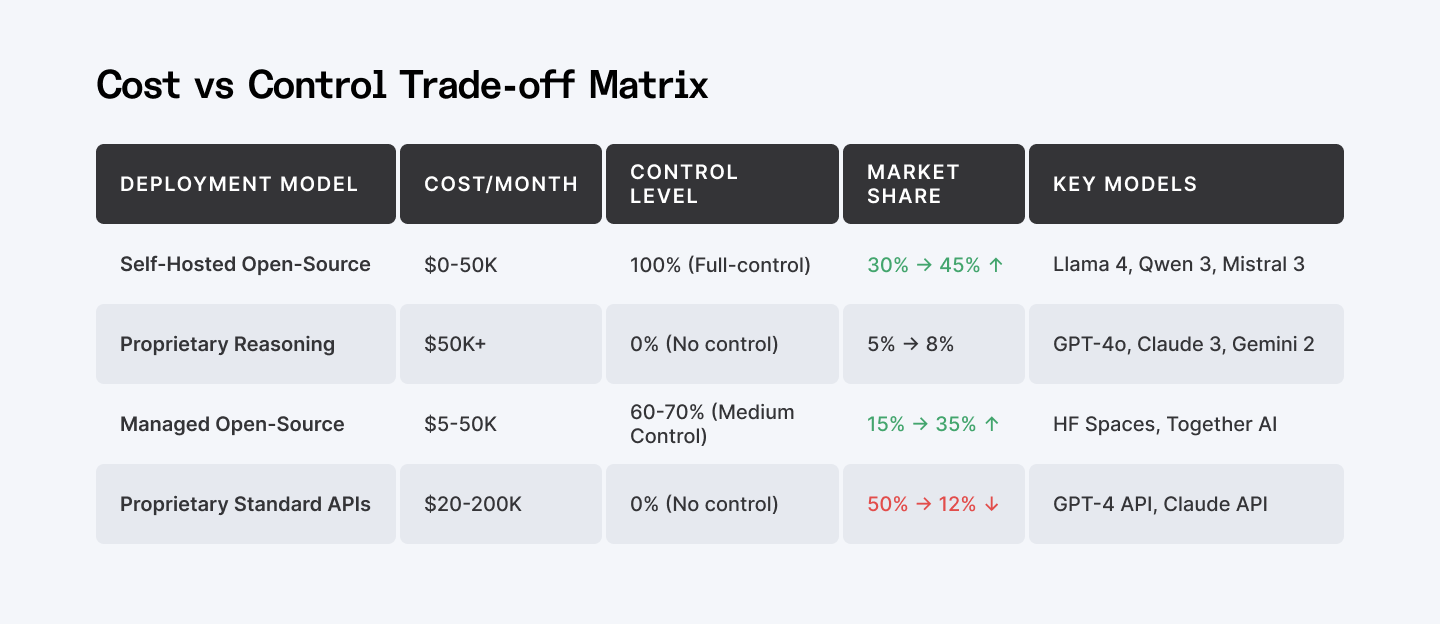
Cost/Control Trade-off Matrix—Self-hosted vs. Proprietary APIs vs. Managed Open-Source
Pinecone's Pinecone Assistant (launched January 2025) chunks, embeds, searches, and reranks automatically. No plumbing required. Weaviate's hybrid search combines semantic vectors with keyword (BM25) retrieval in one query.
Why hybrid search is non-negotiable
RAG systems live or die by retrieval. Vector-only search misses exact terms. Keyword-only search misses semantic meaning.
Hybrid solves both problems.
Your options:
- Pinecone: Sub-100ms latency. Sparse-dense hybrid search. Managed simplicity.
- Weaviate: GraphQL API. On-premise deployment. Multi-tenancy. Full control.
- Qdrant: Speed at scale. Strong open-source support.
- Milvus: Open-source alternative. No vendor dependency.
- Chroma: Lightweight option. Get started in minutes.
Pick your stack based on your constraints. But hybrid search should be your baseline assumption.
Before 2025, RAG pipelines were fragile. Document parsing failed. Wrong chunking destroyed context. Vector search missed exact terms.
2025 fixed it: Docling for intelligent parsing. Hybrid search for semantic + keyword retrieval. Reranking to filter noise. The pipeline matured.
The Bigger Picture: The Market Inverted
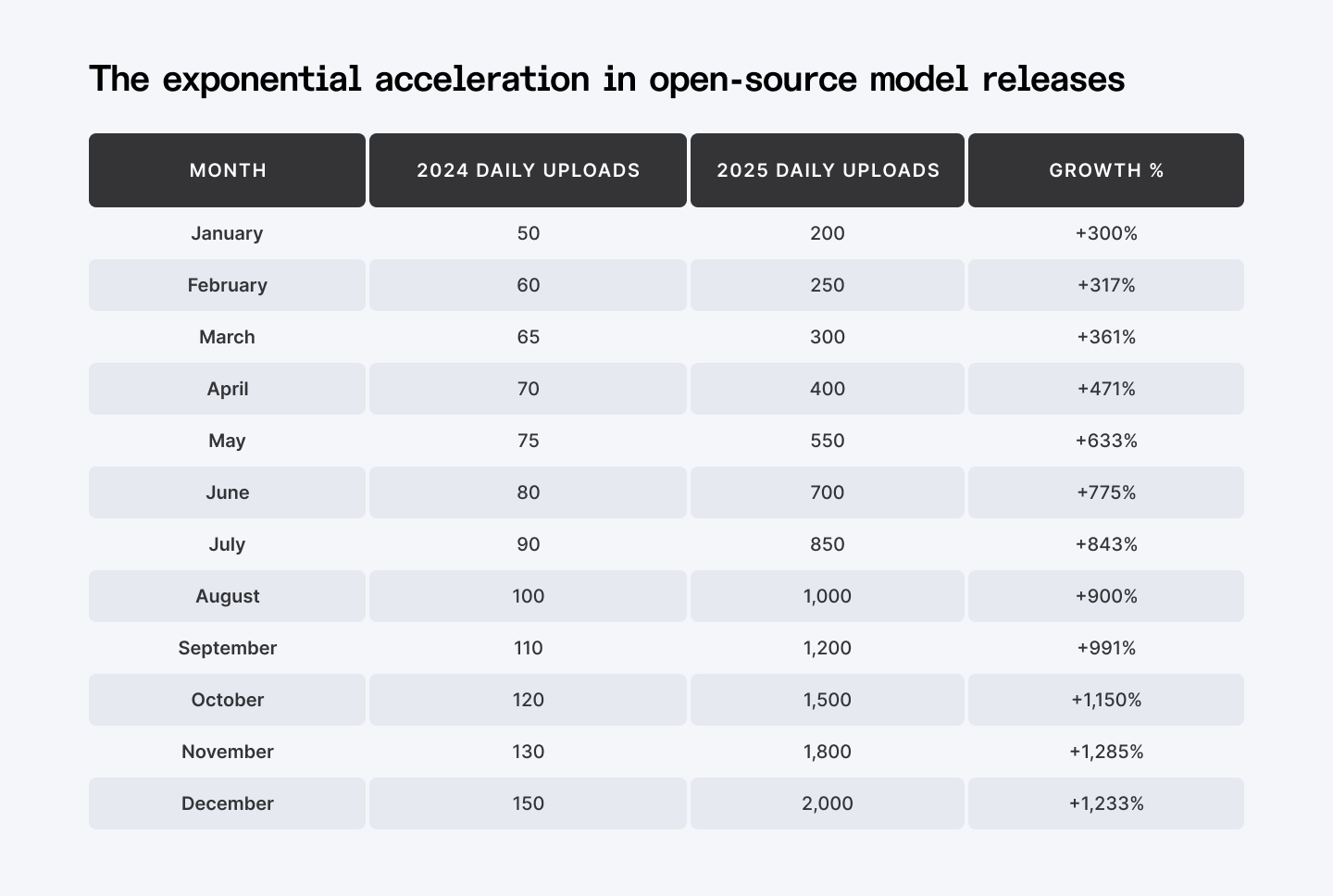
Market Adoption—Daily model uploads to Hugging Face (2024 vs 2025)
Open-source AI isn't fragmented alternatives anymore. It's the infrastructure layer. It's reasoning at scale. It's a multimodal understanding. It's enterprise RAG. It's agentic workflows. All licensed permissively.
The conversation completely inverted.
Five years ago: "Should we take the risk and build on open-source?"
Today: "Why are we still paying per token?"
The second question won. Open-source didn't just catch up. It lapped proprietary vendors while they were arguing about pricing.
What to Do Next
Step 1: Pick a base model
- Llama 4 for general-purpose tasks
- Qwen 3 for multilingual/non-English regions
- DeepSeek R1 for reasoning
- Mistral 3 for edge deployment
Step 2: Test locally
Download Ollama. Run ollama run llama4 or ollama run qwen:3-72b. No cloud. No billing. Thirty seconds.
Step 3: Set up RAG
LlamaIndex or LangChain. Add Docling for document parsing. Wire to Pinecone or Weaviate.
Step 4: Fine-tune if needed
Together AI's platform or Hugging Face Hub. Both integrate directly.
Step 5: Deploy
Hugging Face Spaces for lightweight. Your cloud for scale. Ollama for offline.
Ready to Scale?
The open-source AI landscape isn't theoretical anymore. It's your next production system.
You need engineers who can architect, fine-tune, and deploy at scale. Index.dev connects you with senior developers experienced in LLM deployment, RAG systems, and multimodal reasoning. No API dependency. No vendor lock-in.
Find developers who know the entire stack, from model selection to inference optimization. Explore Index.dev for AI engineering talent →
➡︎ Want to go deeper into where AI is really headed? Explore more Index.dev insights on AI literacy and what it means in 2026, how AI is reshaping application and cloud development, and which industries are closest to a real AI tipping point. You can also dig into practical perspectives on why forward-deployed engineers matter, plus hands-on model comparisons that break down DeepSeek versus ChatGPT, how it stacks up against Claude, and which open-source Chinese LLMs are gaining serious traction.
