A year ago, everyone knew the rule: bigger models = better outputs.
OpenAI had GPT-4. Google had Gemini. Anthropic had Claude. The race was simple: throw more compute, get better results.
Then in January 2026, DeepSeek released a model trained on a fraction of the compute that somehow matched GPT-4's reasoning. Inference cost? 1/100th of OpenAI's.
Overnight, every startup's tech decision from 2024-2025 looked stupid.
We're not here to tell you which model to pick. We're here to tell you the real trade-offs nobody talks about—and why your choice matters way less than you think.
Building AI products in 2026? Index.dev helps you hire engineers who understand inference costs, multi-model architectures, and AI optimization.
Why Everyone Bet on Bigger
For three years (2021-2024), bigger was objectively better.
Not because of physics. Because of economics.
The equation was simple:
- More compute = more performance
- More performance = more customers willing to pay
- More revenue = justify the compute cost
OpenAI could spend $100M training GPT-4 because they'd make $10B in revenue. Startups copied the strategy: 'We'll train our own model. We'll be different.'
Spoiler: Most startups couldn't afford this. So they paid OpenAI for API access instead.
Then everything flipped. Smaller models got efficient. Inference started costing more than training. The economics inverted.
The models didn't change. The business model did.
Cost, Performance, and the Myth of Diminishing Returns
Training Cost vs Inference Cost
Your model choice matters most at inference time, not training time.
If you're using an API (OpenAI, Anthropic), you don't pay for training. You pay per token. At scale, that's brutal.
GPT-4 costs roughly $0.10 per 1,000 tokens (input). DeepSeek costs $0.001 per 1,000 tokens.
GPT-4o costs roughly $2.50 per 1M input tokens and $10 per 1M output tokens. DeepSeek costs $0.28 per 1M input tokens and $0.42 per 1M output tokens.
If you're running a customer support AI with 100K token requests per day:
- GPT-4: $3,000/month
- DeepSeek: $30/month
That's a 100x difference. Not 2x. Not 10x. 100x.
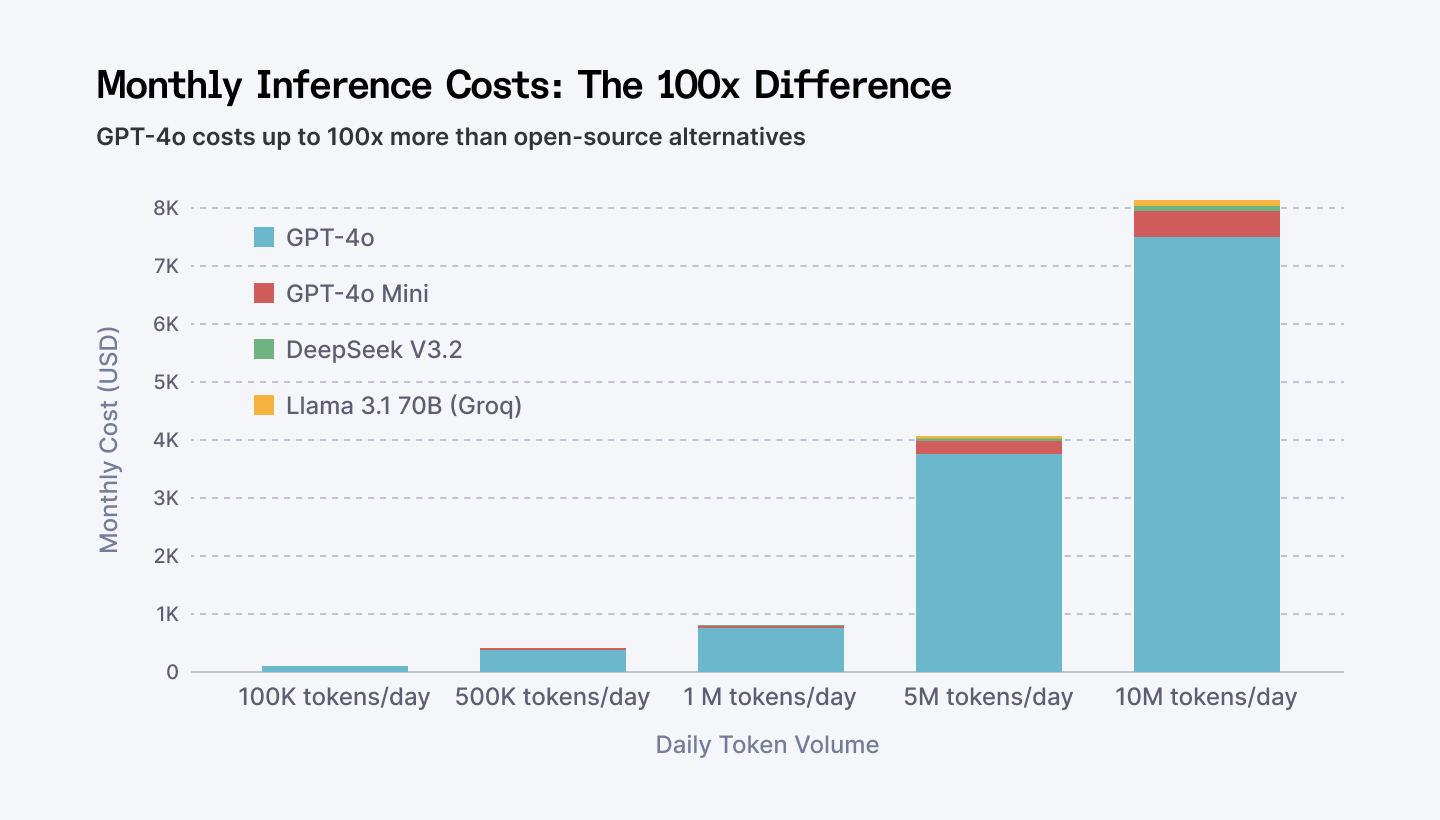
Monthly inference costs scale dramatically between models. At 10M tokens/day, GPT-4o costs nearly $7,500/month vs DeepSeek at $84/month.
But wait. GPT-4 probably solves your problem faster. Has better reasoning. Fewer hallucinations.
So the real question isn't "which is better?" It's "what's your margin on each customer?"
If you're selling customer support at $99/month, GPT-4 margins suck. DeepSeek margins? Insane.
This is why the market is shifting. Not because small models got magically smart. Because economics suddenly made sense.
Performance Gaps
On most benchmarks, small models now match large models from 6-12 months ago.
DeepSeek matches GPT-4 on reasoning. Llama 2 matches Claude on instruction following. Mistral matches Gemini on code generation.
Except... benchmarks are meaningless for your use case.
Your use case isn't MMLU or HumanEval. It's "generate product descriptions" or "summarize support tickets" or "write code review comments."
On real work, the difference between models is: does it work or does it not?
We've seen startups obsess over 2-3% benchmark improvements while their actual product quality didn't change.
The models are good enough now. Picking the "best" one is like picking between Toyota and Honda. Both will work. Pick the one that fits your budget.
Speed Matters. But Only Sometimes.
Small models run faster. Sometimes 10x faster.
This matters if you're building real-time stuff (live chat, code generation, real-time summarization). Your users notice 200ms vs 2 seconds.
If you're doing batch processing overnight, it doesn't matter. Your economics don't care if the job takes 30 minutes or 3 hours.
If you're on API, you don't control latency anyway. Small models run faster. Sometimes 10x faster.
Hallucinations: A Solved Problem (Mostly)
Large models hallucinate less. Fact.
Small models hallucinate more. Also fact.
But you can engineer around hallucinations. Retrieval-augmented generation (RAG) fixes 80% of it. Guardrails fix another 15%. You live with 5%.
It's a solvable problem if you hire smart.
The question isn't "which model has fewer hallucinations?" It's "what's your tolerance for errors, and can you build guardrails around them?"
⭢ Discover the leading Chinese open-source LLMs and how they power AI projects.
What Successful Teams Do Differently
The teams winning in 2026 aren't picking the "best" model. They're picking the right tradeoff. Here's what they do differently.
Pattern #1: They Don't Bet the Company on One Model
- Bad teams: "We're an OpenAI shop."
- Good teams: "We use OpenAI for reasoning, Llama for speed, DeepSeek for cost."
Bad teams built their entire product around GPT-4 APIs. When prices dropped and alternatives emerged, they had to rebuild everything. Sunk cost + wasted months.
Good teams built abstraction layers. They can swap models without rewriting code.
It's boring engineering. But it's the difference between optionality and being stuck.
Pattern #2: They Measure Inference Cost from Day 1
- Bad teams: "Cost optimization is a problem for later."
- Good teams: "Every feature has a cost budget."
Bad teams built features that worked great at $0.10/token, then prices dropped and they realized they're now profitable at $0.001/token.
Good teams knew from day 1: "If we use GPT-4, this feature costs $2K/month. If we use Llama, it costs $200. We need to pick the model that lets us hit our margin targets."
Cost structure drives product decisions. Most teams don't think this way.
Pattern #3: They Hire for Flexibility, Not Specialization
- Bad teams: "We need a GPT-4 expert."
- Good teams: "We need someone who understands inference optimization and can work with any model."
Bad teams hired "LLM engineers" who only knew how to call OpenAI APIs. When the market shifted, their skills became worthless.
Good teams hired engineers with systems thinking. They understand retrieval, caching, batching, quantization. The model is just a variable.
This is where hiring gets critical—good teams don't hire 'GPT-4 experts.' They hire systems thinkers who can work with any model.
Pattern #4: They Test Early, Decide Late
- Bad teams: "Let's pick a model and commit to it."
- Good teams: "Let's run a 2-week test with 3 models and see which one hits our constraints."
Good teams tested: DeepSeek for cost, GPT-4 for quality, Llama for control. Measured the actual difference in their real use case. Picked based on data, not hype.
Bad teams argued about benchmarks.
Your 2025 Tech Decision Was Probably Wrong (But It's Fixable)
If you decided in 2024-2025 to bet on one model, you made a rational decision with the information you had.
But the information has changed.
If you picked GPT-4 for cost reasons: You overpaid.
If you picked Llama for control: You look genius now.
If you picked Claude for reliability: You're fine, but you're also overpaying for something you didn't need.
If you built your own model: You probably wasted millions.
This isn't failure. This is just what happens in fast-moving markets.
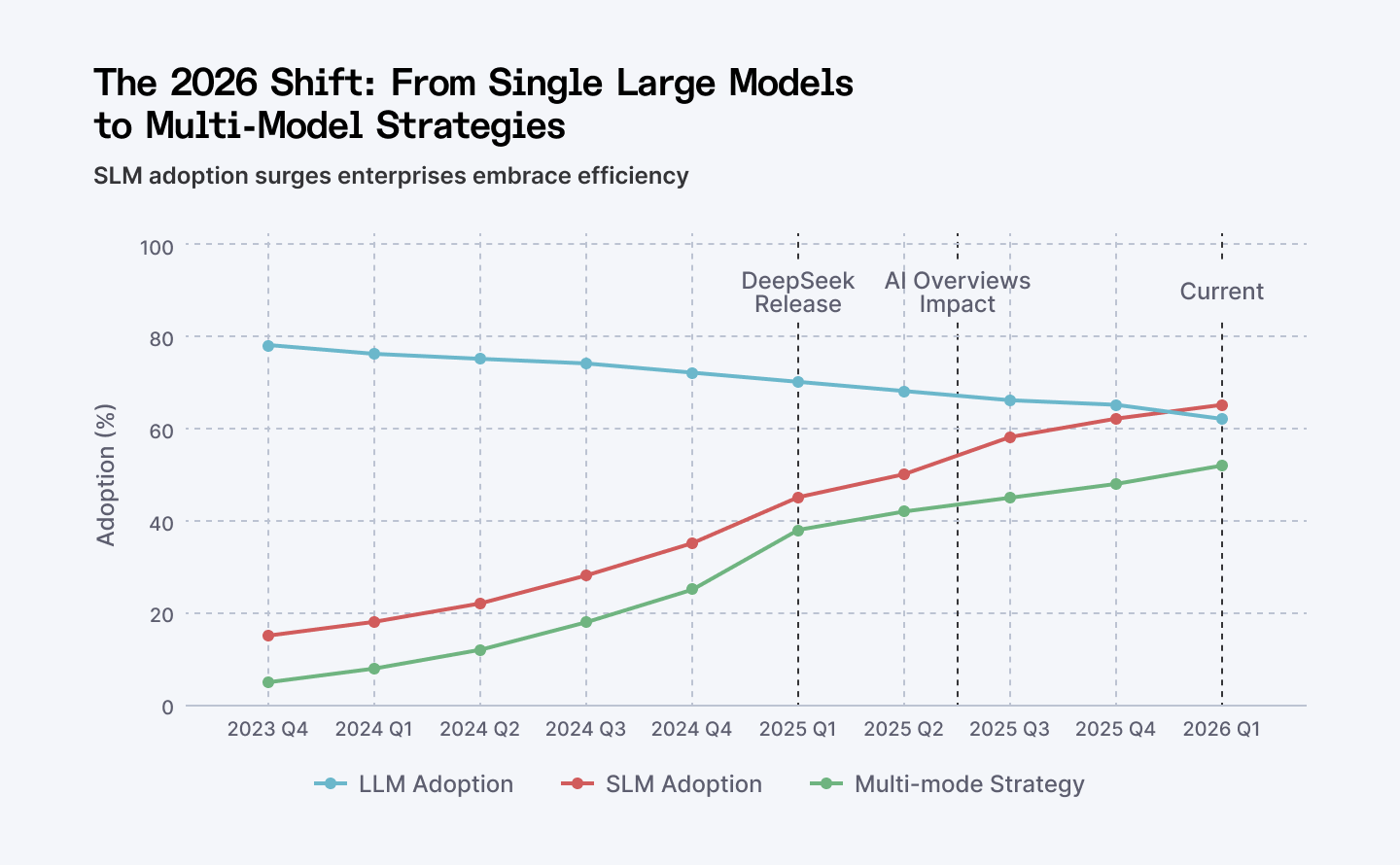
DeepSeek's January 2026 release accelerated a trend that started in mid-2024: enterprises shifting from single large models to hybrid multi-model architectures. The tipping point happened Q3 2025 when SLMs became mainstream.
The winners won't be the ones who picked the right model in 2024. They'll be the ones who can change their mind in 2026. That means:
- Your architecture needs to support model swapping
- Your cost model needs to be flexible
- Your team needs to be smart enough to learn fast
The bad news: Most teams can't do this. They're locked in.
The good news: You can build the ability to change.
⭢ See the top open-source LLMs developers use for coding and building real applications.
Edge Deployment: Where SLMs Win
Here's where the narrative changes completely. Small models aren't just cheaper. They're fundamentally different on the edge.
73% of organizations are moving AI inferencing to edge environments to become more energy efficient. 75% of enterprise-managed data is now created and processed outside traditional data centers.
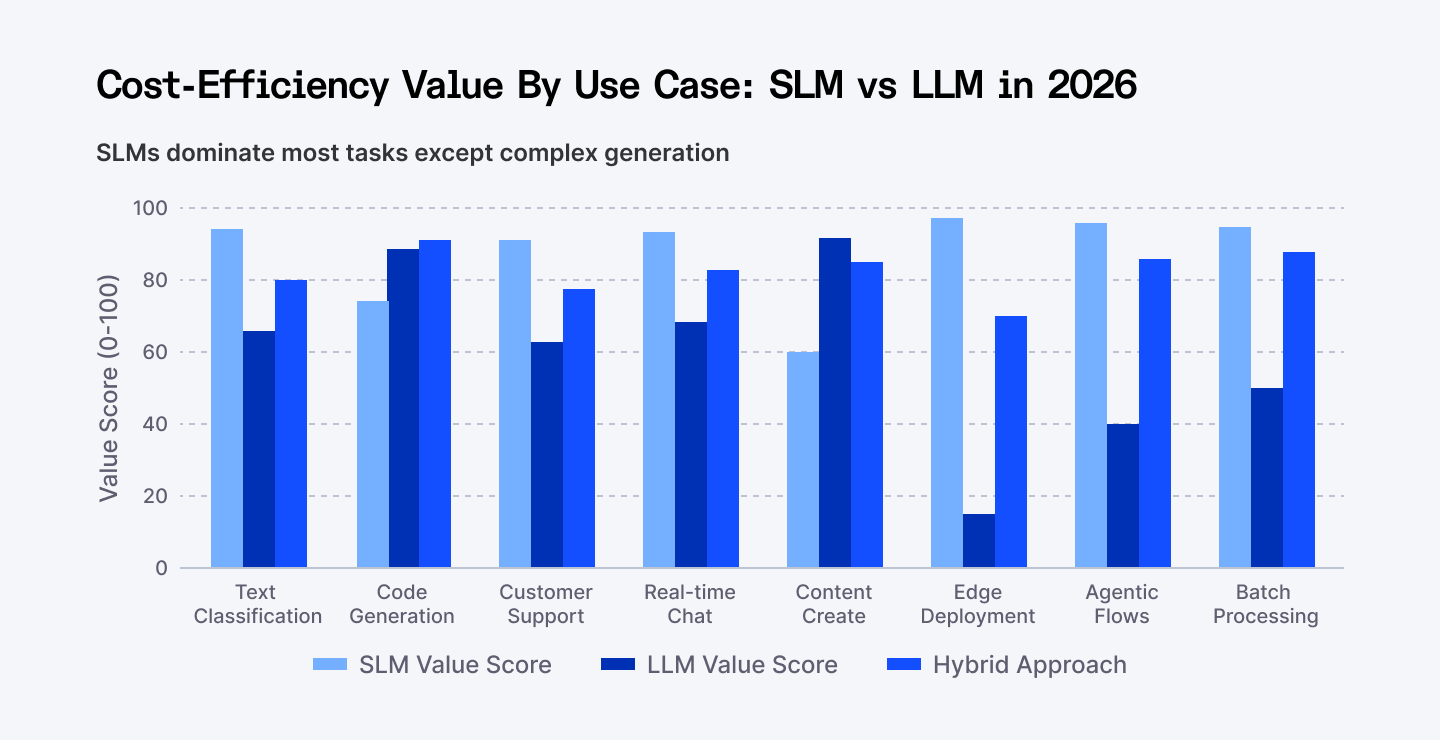
SLMs dominate 6 out of 8 major use cases on cost-efficiency grounds. Hybrid approaches emerging as the 2026 standard for complex applications.
Here's why edge matters: latency disappears. Cost drops further. Data stays local. You control the whole stack.
Small language models designed for edge deployment deliver 80-90% of large model capabilities while running entirely on-device. This isn't a compromise. This is how you build products for the real world.
Quantization
Your teams can deploy models that are 4-8 times smaller than the originals using quantization techniques.
You go from FP32 to INT8. Your model shrinks. Your speed increases. Your accuracy stays nearly the same.
Knowledge Distillation
A smaller "student" model learns from a larger "teacher" model, capturing essential capabilities in a compressed form. This is the tech behind most of the new efficient models.
Pruning
Structured weight pruning removes redundant parameters. You cut out the parts the model doesn't need. Sometimes you get 30% throughput gains and 20% latency improvements from pruning alone.
This compounds. Use all three together? You get compound gains that can mean order-of-magnitude performance improvements.
How to Think About This (Because the Answer Isn't 'Pick Model X')
Step 1: Define Your Constraint
What's your binding constraint?
- Cost? Use the cheapest model that works.
- Latency? Use the fastest model that works.
- Quality? Use the best model you can afford.
- Control? Use the model you can run locally.
Most teams haven't defined this. That's their first mistake.
Step 2: Set Your Budget
"I can afford $X per customer per month for AI inference." Work backwards. If you have 10K paying customers and can spend $100K/month on AI, that's $10/customer/month.
If your model costs $1 per inference and customers make 20 inferences, that's $20. You're already over budget.
This forces you to think about cost structure early.
Step 3: Pick the Model That Hits Your Constraints
Don't pick the "best" model. Pick the one that lets you succeed.
If DeepSeek costs 100x less and does 95% as well as GPT-4, and 95% is enough for your use case, pick DeepSeek. If your use case needs the extra 5%, pick GPT-4.
The decision is mathematical.
Step 4: Build for Change
Your model choice in 2026 might not work in 2028. Build in a way that makes swapping models trivial.
Abstraction layers > tight coupling. Always.
What This Really Means for Startups
Model choice doesn't matter anymore.
What matters is everything else:
- Can your team integrate it?
- Can you monitor it?
- Can you handle when it breaks?
- Can you change it when the market moves?
The startups winning in 2026 aren't the ones with the best model. They're the ones with the best operations.
A mediocre team with GPT-4 will lose to a great team with Llama. A great team with the right ops will beat a genius researcher with a shiny new model.
This is why the hiring market is shifting. VCs stopped asking 'Do you have ML PhDs?' They started asking 'Can you move fast and change course?'
The best AI engineers in 2026 aren't the ones who can build models. They're the ones who can integrate them, monitor them, optimize them, and pivot them.
Your model choice? Table stakes. Your team? Competitive advantage.
What To Watch In 2026
Model Efficiency
Innovations like Gated DeltaNets and Mamba-2 layers are enabling linear attention. These will make small models even faster.
Inference-Time Scaling
Most progress will come from better inference, not training. Speculative decoding. Caching. Better batching. These multiply your model's effective capability without retraining.
Privacy Wins
On-device AI is becoming mainstream. Enterprises will move workloads to the edge aggressively.
Vendor Consolidation
Smaller model companies will struggle. Larger ones will acquire capability-focused startups. Watch for consolidation around specific use cases.
Cost Pressure
Inference costs will keep dropping. This will commoditize simple use cases (summarization, classification, basic Q&A). Margins will compress.
⭢ Find out which LLMs are best for debugging, error detection, and improving code quality.
Conclusion: Pick Based On Constraints
The 2026 truth is simple: bigger stopped being better.
The models are good enough now. Cost, reliability, and speed matter more. Edge deployment is becoming standard, not exceptional. Agentic systems are becoming real products, not experiments.
Teams that understood this early are moving fast. Teams that are still betting the company on one large model are at risk.
So which model should you pick?
Pick the one that lets you sleep at night knowing you can change it. Pick the one that hits your cost constraint without sacrificing quality. Pick the one that your team can integrate fastest.
And then build your company like model choice is a variable, not a destiny.
The market moved once. It'll move again.
Winners aren't the ones who picked right. They're the ones who can move fast.
➡︎ Building AI products in a world where models change every 6 months? Your competitive advantage isn’t picking GPT-4, DeepSeek, or the next trending model. It’s building a team that can evaluate tradeoffs, control inference costs, design multi-model architectures, and adapt when the market shifts again. At Index.dev, we connect you with engineers who understand optimization, edge deployment, RAG pipelines, quantization, and cost-aware AI architecture — not just API integrations.
➡︎ Want to go deeper into where AI is really headed? Explore more Index.dev insights on AI literacy and what it means in 2026, how AI is reshaping application and cloud development, and which industries are closest to a real AI tipping point. You can also dig into practical perspectives on why forward-deployed engineers matter, plus hands-on model comparisons that break down DeepSeek versus ChatGPT, how it stacks up against Claude, and which open-source Chinese LLMs are gaining serious traction.
