A large language model (LLM) is a deep learning method that can handle a wide range of natural language processing (NLP) tasks. Large language models use transformer models and are trained on vast datasets, hence the term "large." This allows them to recognize, translate, predict, and create text or other content. Large language models, commonly known as neural networks (NNs), are computational systems inspired by the human brain. These neural networks use a network of stacked nodes, similar to neurons.
In addition to teaching human languages to artificial intelligence (AI) applications, large language models can be trained to do a range of tasks such as recognizing protein structures, generating software code, and so on. Large language models, like the human brain, must be pre-trained before being fine-tuned to address tasks such as text categorization, question answering, document summarising, and text production. Their problem-solving abilities can be employed in industries such as healthcare, banking, and entertainment, where large language models serve a wide range of NLP applications such as translation, chatbots, AI assistants, and so on.
Large language models also include an elevated number of parameters, which are similar to memories that the model accumulates as it learns during training. Consider these parameters as the model's knowledge bank.
Key Components of LLMs
Large language models are made up of several neural network layers. Recurrent layers, feedforward layers, embedding layers, and attention layers work together to process input text and produce output content.
The embedding layer generates embeddings from supplied text. This component of the large language model captures the semantic and syntactic meaning of the input, allowing the model to grasp context.
A large language model's feedforward layer (FFN) consists of numerous fully connected layers that alter input embeddings. These layers allow the model to extract higher-level abstractions, i.e. interpret the user's intent with the text input.
The recurrent layer evaluates each word in the incoming text in order. It describes the relationship between the words in a phrase.
The attention mechanism allows a language model to focus on specific bits of input text that are relevant to the job at hand. This layer enables the model to produce the most accurate results.
There are three primary types of large language models:
Generic or raw language models anticipate the next word using the language in the training data. These language models carry out information retrieval tasks.
Instruction-tuned language models are taught to predict how the input's instructions will be followed. This enables them to perform sentiment analysis and generate text or code.
Dialog-tuned language models are trained to engage in a conversation by anticipating the next response. Think about chatbots or conversational AI.
How a Large Language Model is Built?
A "large language model" is a large-scale transformer model that is generally too large to execute on a single machine and is thus supplied as a service via an API or web interface. These models are trained using massive volumes of text data from books, papers, webpages, and other forms of written information. By examining the statistical correlations between words, phrases, and sentences during the training process, the models can provide logical and contextually relevant responses to prompts or questions.
ChatGPT's GPT-3, a huge language model, was trained using massive volumes of internet text data, allowing it to grasp multiple languages and topics. As a result, it may output text in a variety of styles. While its skills, such as translation, text summarization, and question answering, may appear amazing, they are unsurprising given that these operations use particular "grammars" that correspond to prompts.
How Do LLMs Work?
Machine Learning and Deep Learning
LLMs are fundamentally based on machine learning. Machine learning is a subset of artificial intelligence that refers to the technique of providing huge volumes of data to a software in order to train it to detect properties of that data without the need for human interaction.
LLMs employ a form of machine learning known as deep learning. Deep learning models may effectively train themselves to discern distinctions without human interaction, however some human fine-tuning is usually required.
Deep learning employs probability in order to "learn." For example, in the sentence "The quick brown fox jumped over the lazy dog," the letters "e" and "o" appear four times each. A deep learning model could determine correctly that these characters are among the most likely to appear in English-language text.
In reality, a deep learning model cannot conclude anything from a single sentence. However, after analysing trillions of sentences, it may have learned enough to predict how to logically complete an unfinished statement or even construct its own sentences.
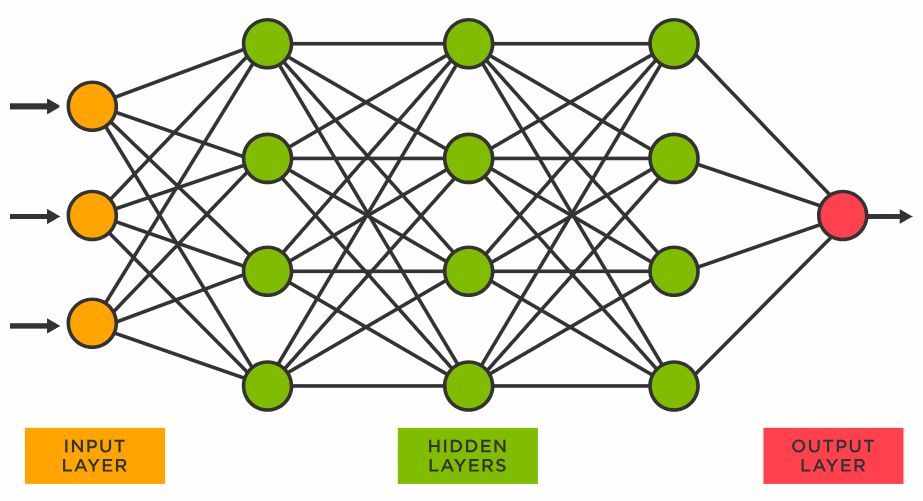
Neural Networks
Neural networks are used to build LLMs, which enable this form of deep learning. An artificial neural network is made up of network nodes that communicate with one another, just like the neurons in the human brain. They are made up of multiple "layers": an input layer, an output layer, and one or more levels in between. The layers only share information if their own outputs exceed a specified threshold.
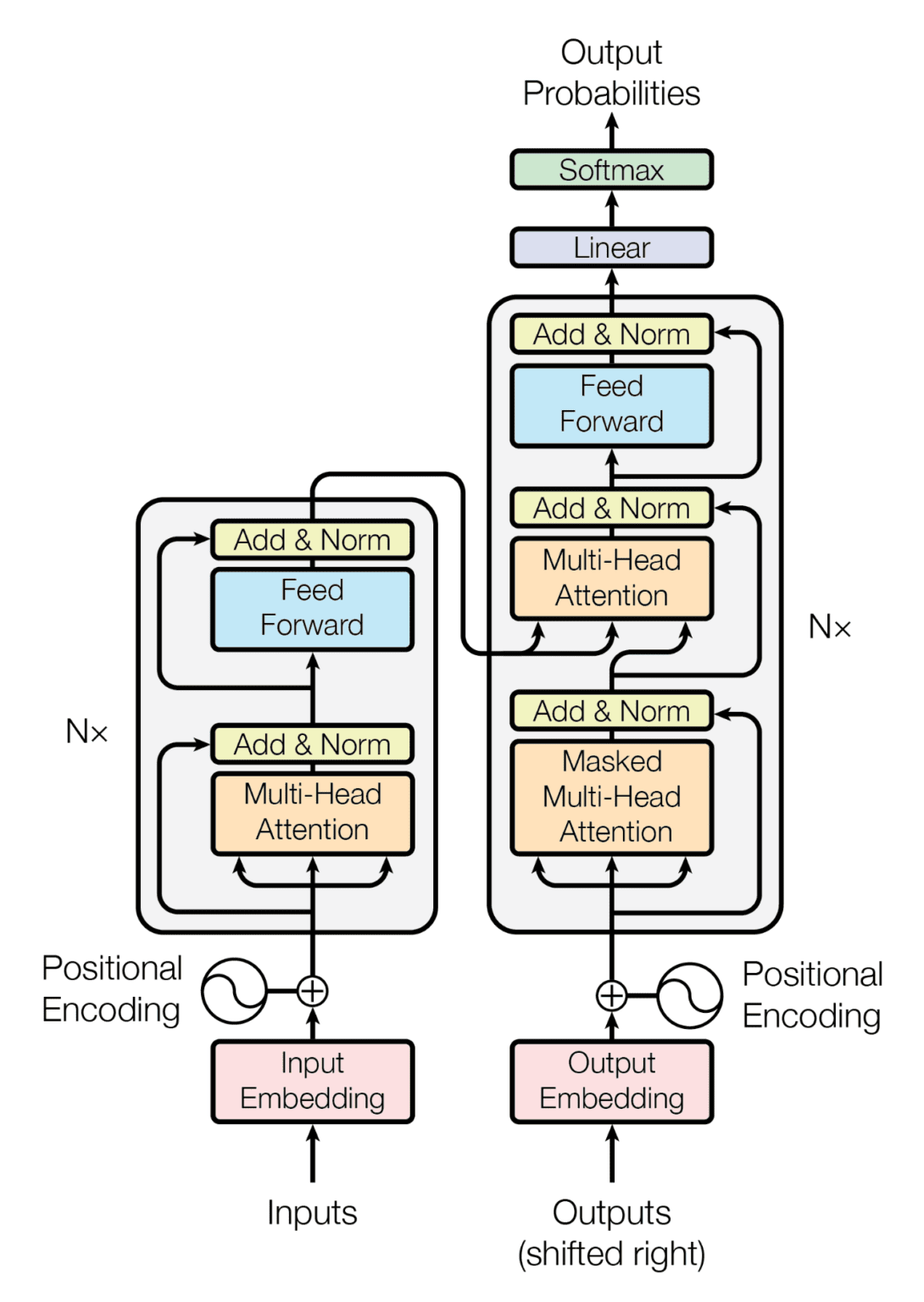
Transformer Models
Transformer models are the special type of neural network employed for LLMs. Transformer models can learn context, which is especially useful for human language, which is heavily context-dependent. Transformer models use a mathematical approach known as self-attention to find subtle relationships between items in a sequence. As a result, they outperform other types of machine learning in terms of context comprehension. It helps children comprehend how the conclusion of a phrase ties to the beginning, as well as how sentences in a paragraph relate to one another.
This enables LLMs to read human language, even when it is ambiguous or poorly defined, structured in unfamiliar combinations, or contextualised in novel ways. On some level, they "understand" semantics since they can correlate words and concepts based on their meaning after seeing them grouped together millions or billions of times.
Why Transformer Can Predict Text?
Andrej Karpathy's blog post "Unreasonable Effectiveness of Recurrent Neural Networks" revealed that recurrent neural networks can reasonably anticipate the next word of a text. Not only are there restrictions in human language (i.e., grammar) that restrict the usage of words in different parts of a phrase, but there is also redundancy in language.
According to Claude Shannon's seminal article "Prediction and Entropy of Printed English," the English language has an entropy of 2.1 bits per letter, despite having 27 letters (including spaces). If letters were chosen at random, the entropy would be 4.8 bits, making it easier to predict what happens next in a human language document. Machine learning models, particularly transformer models, are capable of producing such predictions.
Repeating this technique allows a transformer model to generate the full passage word for word. However, what does grammar mean in the context of a transformer model? Grammar refers to how words are used in language, dividing them into separate parts of speech and requiring a certain order inside a phrase. Despite this, enumerating all grammar rules is tough. In actuality, the transformer model does not explicitly store these rules; instead, it learns them implicitly from examples. It is possible that the model can learn more than only grammatical rules, such as the ideas described in those examples, but the transformer model must be large enough.
From Transformer Model to Large Language Model
Humans interpret text as a collection of words. Sentences are word sequences. Documents consist of chapters, sections, and paragraphs. Text, on the other hand, is nothing more than a sequence of characters to computers. To enable machines to interpret text, a model based on recurrent neural networks can be developed. This model processes one word or character at a moment, returning an output once the entire input text has been consumed. This approach works reasonably well, with the exception that it occasionally "forgets" what happened at the start of the sequence when the end is reached.
Vaswani et al. released "Attention is All You Need," a study in 2017, to build a transformer model. It's based on the attention process. In contrast to recurrent neural networks, the attention mechanism allows you to perceive the full sentence (or even the paragraph) at once, rather than one word at a time. This helps the transformer model understand the context of a word better. Transformers serve as the foundation for several cutting-edge language processing algorithms.
The context vector represents the core of the entire input. Using this vector, the transformer decoder produces output depending on cues. For example, you can use the original input as a hint and let the transformer decoder generate the next word that naturally follows. Then you can use the same decoder again, but this time the hint will be the previously generated next-word. This technique can be repeated to form a full paragraph, beginning with a leading sentence.
This approach is known as autoregressive generation. This is how a huge language model works, with the exception that it is a transformer model that can accept very long input text, has a large context vector to handle very complicated concepts, and has several layers in its encoder and decoder.
Limitations and Challenges of LLMs
Large language models may create the impression that they grasp meaning and can respond to it correctly. However, they continue to be a technological tool, and as such, large language models face a number of issues.
1 - Hallucinations - A hallucination occurs when an LLM produces an output that is false or does not fit the user's intention. For example, professing to be human, to have feelings, or to love the user. Because large language models predict the next syntactically valid word or phrase, they are unable to fully understand human meaning. The outcome might sometimes be referred to as a "hallucination."
2 - Security - Large language models provide significant security threats if not controlled and monitored correctly. They are capable of leaking private information, participating in phishing scams, and producing spam. Users with ill intent can program AI to reflect their views or biases, contributing to the spread of disinformation. The consequences can be disastrous on a worldwide scale.
3 - Bias - The data used to train language models has an impact on the models' outputs. As a result, if the data represents a single demography or is lacking in diversity, the large language model's outputs will be similarly lacking.
4 - Consent - Large language models are trained using trillions of datasets, some of which may not have been collected consensually. When scraping data from the internet, big language models have been known to disregard copyright licenses, plagiarise written content, and repurpose proprietary content without the permission of the original owners or artists. When it generates results, there is no way to trace the data history, and producers are frequently not credited, exposing consumers to copyright infringement risks.
5 - Scaling - Scaling and maintaining large language models can be time and resource intensive.
6 - Deployment - Large language models necessitate deep learning, a transformer model, distributed software and hardware, and extensive technical knowledge.
LLM Use Cases
LLMs are reinventing an increasing number of business processes, and they have demonstrated their adaptability across a wide range of use cases and jobs in numerous industries. They supplement conversational AI in chatbots and virtual assistants (such as IBM Watson Assistant and Google's BARD) to improve the interactions that underpin excellent customer service by giving context-aware responses that resemble conversations with human agents.
LLMs excel in content generation, automating the creation of blog articles, marketing or sales materials, and other writing jobs. They help researchers and academics summarise and extract information from large databases, hence expediting knowledge discovery. LLMs also play an important role in language translation, bridging language gaps by producing accurate and contextually relevant translations. They can even be used to create code or "translate" between programming languages.
Furthermore, they help people with disabilities by using text-to-speech apps and creating content in accessible formats. From healthcare to finance, LLMs are revolutionising industries by optimising operations, increasing consumer experiences, and allowing for more efficient and data-driven decision making.
Most excitingly, all of these capabilities are easily accessible, with some only requiring an API integration.
Here is a summary of some of the most critical areas where LLMs help organisations:
Text Generation - Language generation skills, such as the ability to write emails, blog posts, or other medium-to-long length content in response to prompts, can be honed and polished. One excellent example is retrieval-augmented generation (RAG).
Content Summarization - Long articles, news items, research papers, company paperwork, and even customer history can be summarised into thorough texts that are length-matched to the output format.
AI Assistants - Chatbots that respond to client inquiries, conduct backend activities, and deliver precise information in natural language as part of an integrated, self-service customer care system.
Code Generation - supports developers in constructing apps, detecting code errors, and identifying security flaws across many programming languages, even "translating" them.
Sentiment Analysis - Analyze text to determine the customer's tone in order to understand customer feedback on a large scale and assist with brand reputation management.
Language Translation - Fluent translations and multilingual capabilities expand enterprises' coverage across languages and locations.
LLMs have the potential to transform every business, from finance to insurance, human resources to healthcare, and beyond, by automating client self-service, shortening response times on an expanding number of activities, and delivering more accuracy, improved routing, and smarter context collection.
NLP and LLM Integration
Fusing NLP and LLMs is a big step forward in the development of advanced language processing systems. This partnership brings together NLP's exact skills with LLM's extensive contextual knowledge. It has the potential to dramatically improve the efficiency and efficacy of AI applications in several industries.
Integrating NLP with LLM technologies offers several key advantages:
Enhanced Accuracy and Contextual Understanding - Combining NLP's targeted processing strengths with LLM's broad contextual comprehension increases the accuracy and relevance of language tasks.
Resource Optimization - NLP's efficiency in specific task processing complements LLM's resource-intensive nature. It leads to scalable solutions and more efficient use of computer resources.
Increased Flexibility and Adaptability - Combining these technologies improves the flexibility and adaptability of AI systems. They can grow more adaptable to changing requirements.
Open Source Models - About Code Llama, 2023
The availability of open-source LLMs has transformed the area of natural language processing, allowing researchers, developers, and businesses to create applications that utilise the capabilities of these models to construct products at scale for free.
Meta's latest Code LLM, Code Llama, outperforms all other open-source models on a variety of benchmark datasets. It scores 53% on the HumanEval dataset and 55% on the MBPP dataset (only GPT-4 performs better). These advances can be attributed to a 16K context length (4x that of Llama2) and training pre-trained Llama 2 on an additional 500B tokes from Program and Natural Language.
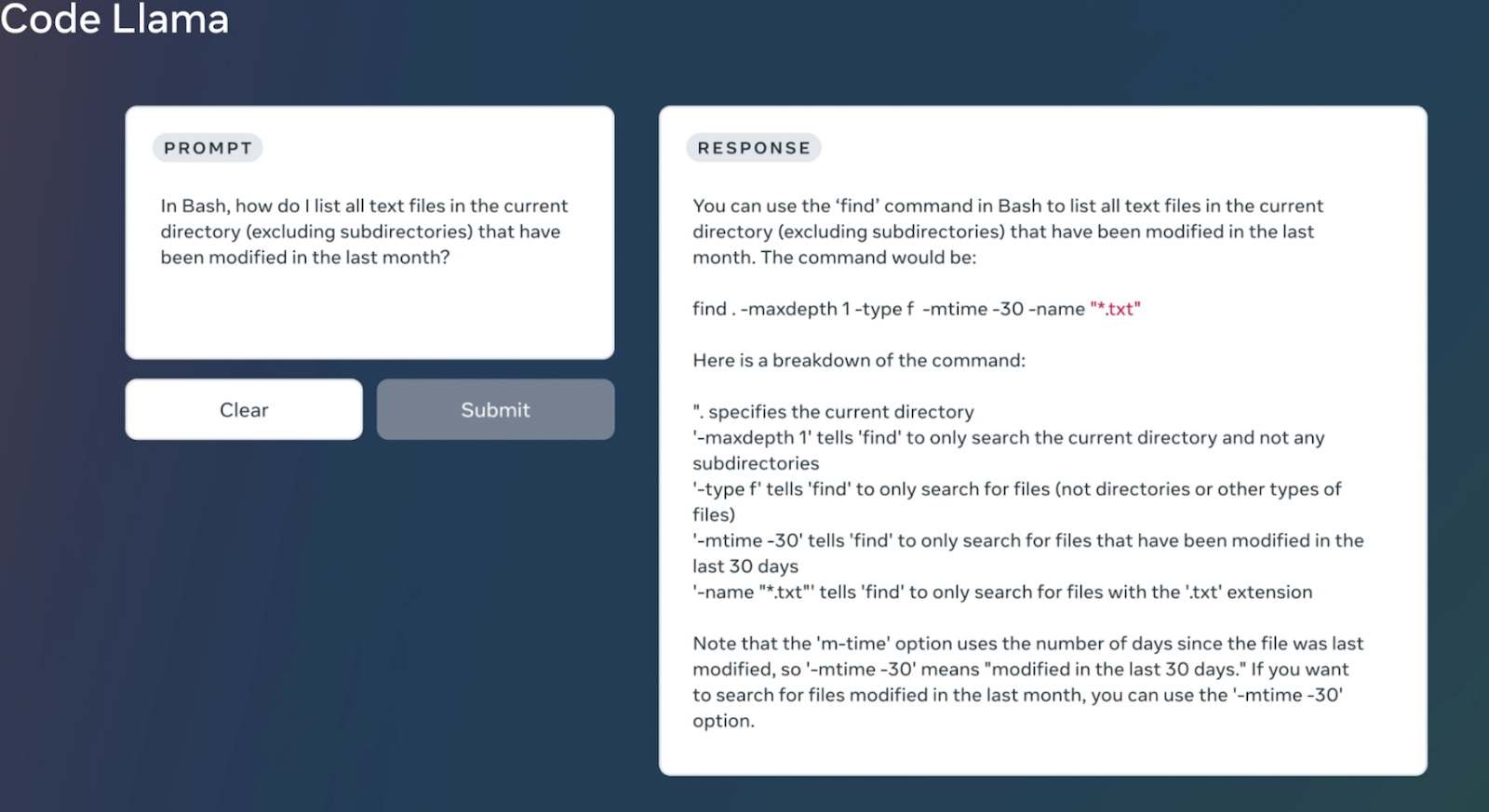
This approach is ideally suited for code generation and infilling activities, and can serve as an excellent copilot during IDE-based software development. The Code Llama models family contains three sorts of models:
- Code Llama
- Code Llama Python
- Code Llama-Instruct

Training Dataset: 500B tokens + additional 100B tokens for Code llama Python on publicly available code
Model Architecture: Llama 2
Parameter Size: Available in 3 sizes — 7B, 13B and 34B.
Novelty:
- Proposed a fine-tuning step to handle long sequences called Long Context Fine-Tuning, which increases context length to 16,384 (4x from Llama 2 context length, which is 4096).
- Instruction Fine Tuning & Self-Instruct: One of the few models that performs instruction fine-tuning, employing explicit instructions or prompts throughout the process. Instead of generating costly human feedback data, the authors offer a novel execution feedback strategy for building a self-instruction dataset.
How Code Llama Works?
Code Llama is a code-specialized variant of Llama 2 that was built by training Llama 2 on code-specific datasets and collecting more data from the same dataset for longer periods of time. Code Llama is essentially an extension of Llama 2 that provides improved coding skills. It can produce code as well as natural language about code from both code and natural language prompts (for example, "Write me a function that outputs the fibonacci sequence.") It is also useful for code completion and debugging. It supports many of today's most popular programming languages, including Python, C++, Java, PHP, Typescript (Javascript), C#, and Bash.

LLMs With Python
Python, a popular computer language, provides various packages for interacting with LLMs.
Transformers: This core collection includes pre-trained LLM models and tools for fine-tuning and applying them to your tasks.
OpenAI API: A premium API provides access to sophisticated LLMs such as GPT-3, allowing for advanced capabilities.
Hugging Face Hub: This active community network provides a variety of LLM models and tools, making experimenting possible.

This code will continue the story based on the prompt, demonstrating the LLM's capacity to generate text that adheres to the theme and style.
Here's a Python code example that shows sentiment analysis using the Transformers module.

- Import the pipeline: The transformers library's pipeline function loads a pre-trained LLM model to do sentiment analysis.
- Initialise the pipeline: The sentiment-analysis pipeline is specifically intended for sentiment categorization.
- Prepare sentences: A list of example sentences is compiled for analysis.
- Analyse sentiment: The sentiment_analyzer function accepts each sentence as input and returns a dictionary comprising
- Label: Predicted sentiment label (e.g., "POSITIVE", "NEGATIVE", "NEUTRAL").
- Score: A numerical score expressing the confidence of the prediction (ranges from 0 to 1)
- Print results: To ensure clarity, the code prints both the sentence and the sentiment analysis.
Comparative Analysis of LLMs
| Model | GPT-3 | BERT | XLNet | T5 | RoBERTa |
| Developer | OpenAI | Carnegie Mellon University & Google | Facebook AI Research | ||
| Parameters | 175 billion | 340 million | 340 million | 11 billion | 355 million |
| Training Approach | Autoregressive | Masked Language Model (MLM) | Permutation Language Modeling | Text-to-Text | Masked Language Model (MLM) |
| Pre Training Data | Diverse | Wikipedia + BookCorpus | Diverse | Diverse | Diverse |
| Fine-Tuning | Yes | Yes | Yes | Yes | Yes |
| Tasks Supported | Text generation, translation, summarization, etc. | Contextual understanding, question answering, etc. | Language modelling, question answering, etc. | Text-to-text transformations, question answering, summarization, etc. | Language understanding, question answering, etc. |
| Notable Features | Large parameter size, diverse capabilities | Bidirectional understanding of context | Permutation language modelling | Text-to-text transformations | Robust optimization approach |
The Future of LLMs
The emergence of large language models capable of answering questions and generating text, such as ChatGPT, Claude 2, and Llama 2, foreshadows fascinating future possibilities. LLMs are slowly but steadily approaching human-like performance. The initial success of these LLMs reveals a strong interest in robotic-type LLMs that mimic, and in some cases outperform, the human brain. Here are some opinions about the future of LLMs.
Increased Capabilities - As remarkable as they are, the current state of technology is not flawless, and LLMs are not infallible. Newer releases, on the other hand, will have more accuracy and capability as engineers understand how to improve performance while lowering bias and eliminating wrong replies.
Audiovisual Trainings - While most LLMs are trained using text, several companies have begun training models with video and audio input. This type of training should accelerate model development and bring up new options for using LLMs in autonomous cars.
Workplace Transformation - LLMs are a disruptive force that will transform the workplace. LLMs are likely to eliminate dull and repetitive activities in the same way that robots reduced repetitive industrial chores. Possible applications include repetitious secretarial jobs, customer service chatbots, and simple automated copywriting.
Conversational AI - LLMs will likely boost the performance of automated virtual assistants such as Alexa, Google Assistant, and Siri. They will be able to better understand human intent and respond to complex requests.
Demand Surges for LLM Engineers: Shaping the Future of Technology - In a rapidly evolving technological landscape, the demand for LLM (Language, Logic, and Mathematics) engineers is reaching new heights. Companies across industries are increasingly recognizing the value of these interdisciplinary experts who possess a unique blend of linguistic prowess, logical reasoning, and mathematical acumen. From developing cutting-edge AI algorithms to crafting natural language processing systems, LLM engineers are at the forefront of innovation, driving progress and shaping the future. As organizations seek to harness the power of data and automation, the hunt for talented LLM engineers intensifies, marking a pivotal moment in the evolution of technology-driven industries.
Conclusion
Large Language Models (LLMs) have revolutionised natural language processing, enabling new advances in text generation and comprehension. LLMs can learn from massive data, comprehend its context and entities, and respond to user inquiries. This makes them an excellent choice for regular use in a variety of industries. However, there are worries regarding the ethical implications and possible biases of these models. LLMs must be approached critically and their impact on society evaluated. LLMs have the potential to bring about positive changes in many sectors if used carefully and developed further, but we must be conscious of their limitations and ethical consequences.